Apache Spark — это мощный фреймворк для обработки больших объемов данных в распределенной среде. Он предоставляет разнообразные инструменты и библиотеки для обработки и анализа данных, а также поддерживает распараллеливание для оптимальной работы с множеством узлов кластера. Распараллеливание в Spark позволяет выполнять операции на кластере в параллельном режиме, что значительно увеличивает производительность обработки данных. Spark предоставляет несколько настроек, которые позволяют контролировать уровень распараллеливания и оптимизировать выполнение задач. В этой статье мы рассмотрим, как правильно настроить распараллеливание в Spark.
Особенности конфигурации и распараллеливание в Spark: несколько практических примеров
Основные параметры для настройки распараллеливания в Spark включают:
- Количество параллельных задач (tasks): Это количество задач, которые Spark может выполнять одновременно на узлах кластера. Оно зависит от количества ядер (CPU cores) и доступной памяти на каждом узле.
- Распределение данных (data partitioning): Spark разбивает входные данные на части, называемые разделами (partitions), и обрабатывает каждую часть параллельно. Вы можете управлять количеством разделов, чтобы более равномерно распределить нагрузку на узлах кластера.
- Распределение задач (task distribution): Spark может автоматически распределять задачи между узлами кластера. Однако иногда вы можете управлять этим процессом вручную, чтобы оптимизировать выполнение задач.
Настройка количества разделов позволяет контролировать, как Spark разбивает данные на части для обработки. Для этого можно использовать метод repartition() на RDD (Resilient Distributed Dataset) или DataFrame:
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
# Инициализация Spark
conf = SparkConf().setAppName("ParallelismExample")
sc = SparkContext(conf=conf)
spark = SparkSession(sc)
# Загрузка данных из файла
data = spark.read.text("data.txt")
# Установка количества разделов
data = data.repartition(4) # Устанавливаем 4 раздела
Можно настроить количество задач, выполняемых на узлах кластера, с помощью параметра spark.default.parallelism. Этот параметр определяет количество задач по умолчанию, но его также можно изменить в зависимости от конкретных потребностей задачи:
spark.conf.set("spark.default.parallelism", 6) # Устанавливаем 6 задач по умолчанию
Spark автоматически распределяет задачи между узлами кластера, но иногда вам может потребоваться более тонкая настройка. Вы можете использовать метод foreachPartition() для выполнения определенных операций на каждом разделе данных:
def process_partition(iterator): # Код обработки данных pass data.rdd.foreachPartition(process_partition)
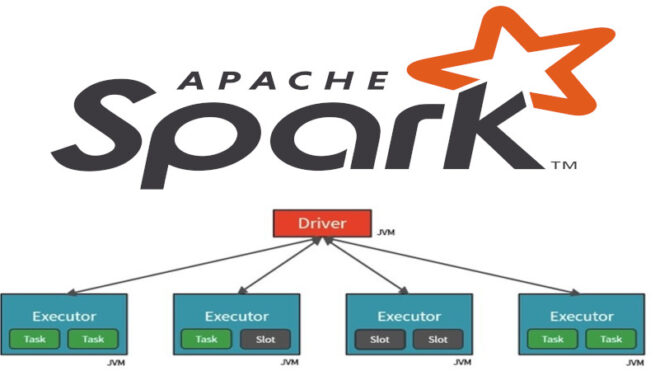
Исполнители (Executors) — это вычислительные узлы в кластере, которые выполняют задачи Spark. Распараллеливание в Spark позволяет выполнять операции на исполнителях параллельно, что значительно увеличивает производительность обработки данных. Spark автоматически управляет исполнителями, но вы можете настроить их для оптимизации выполнения задач. Можно динамически настраивать параметры исполнителей внутри Spark приложения. Например, можно использовать метод config() для настройки параметров:
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("ExecutorExample")
sc = SparkContext(conf=conf)
# Настройка числа исполнителей и их памяти внутри приложения
sc._conf.set("spark.executor.instances", "4")
sc._conf.set("spark.executor.cores", "2")
sc._conf.set("spark.executor.memory", "4g")
Spark предоставляет веб-интерфейс для мониторинга и управления исполнителями. Вы можете получить доступ к нему, перейдя по адресу http://<driver-node>:4040, где <driver-node> — это адрес вашего драйвера Spark. С этого интерфейса вы сможете наблюдать работу исполнителей, а также просматривать журналы и профилировать задачи.
Таким образом, понимание основных параметров и методов для управления распараллеливанием позволит эффективно использовать мощности и ресурсы кластера.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
21 сентября, 2026
Продолжительность
20 ак.часов
Стоимость обучения
64 000 руб.
Это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика распределенных Big Data приложений.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:

