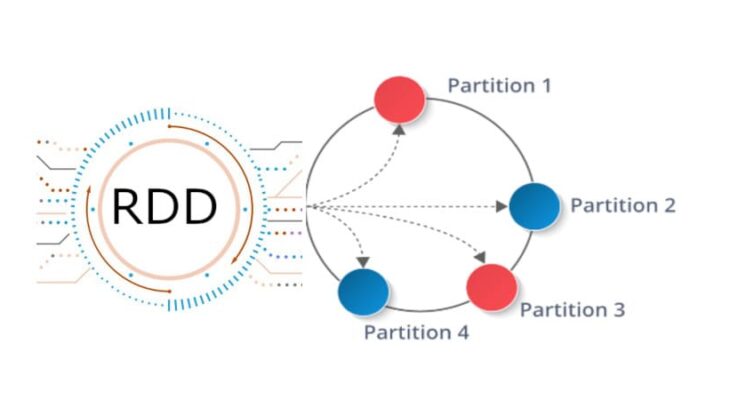
RDD (Resilient Distributed Dataset) — это простая, неизменяемая, распределенная коллекция объектов во фреймворке Apache Spark. RDD представляет собой распределенный набор данных, который делится на множество частей, обрабатывающихся различными узлами в кластере. Наборы РДД могут содержать объекты с любыми типами данных на языках Python, JAVA или Scala [1].
Как устроен RDD: свойства и структура
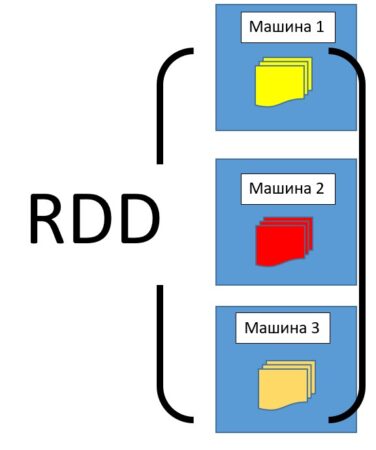
RDD – это разновидность датасета (простого набора данных), который разделен на множество машин, работающих в кластере.
RDD имеет следующие свойства:
- Неизменяемость и секционирование – РДД состоит из набора записей, которые делятся на разделы. Раздел — это единица параллелизма в РДД. Каждый раздел является логическим подразделением данных, которое является неизменяемым (immutable) и хранится на отдельном узле в кластере.
- Применение общих операций (coarse-grained operations), которые способны манипулировать всеми данными одновременно (например, фильтр или группировка).
- Отказоустойчивость: все преобразования над наборами РДД ведутся в распределенной среде с поддержкой репликации (копированием данных между узлами), и каждое преобразование регистрируется каждым отдельным узлом в кластере. Следовательно, при выходе из строя одного узла, данные можно будет восстановить с помощью любого другого рабочего узла.
- Ленивые вычисления: Apache Spark проводит необходимые преобразования над РДД только один раз в момент их создания. Это значительно сокращает общее время выполнения всех операций и ускоряет работу над данными.
- Сохраняемость: пользователи могут выбирать удобный для себя формат хранения РДД (например, в памяти или на диске в файле).
RDD можно создавать вручную, а можно загружать из внешних источников. Источниками хранения РДД могут служить следующие источники:
- текстовый файл;
- CSV-файл;
- файл со структурой JSON-документа;
- база данных (через драйвер JDBC) [1].
Как появился RDD: краткая история Apache Spark
Работа над структурой RDD началась в 2009 году. Это было связано с идеей проекта для распределенной работы с данными – Apache Spark. Таким образом, наборы РДД стали неотъемлемой частью Spark, автором которого является румынско-канадский ученый в области информатики Матей Захария.
В 2010 году проект был опубликован под лицензией BSD (Berkeley Software Distribution), а уже в 2013 году передан фонду Apache и переведен на лицензию Apache 2.0. В 2014 году был принят в число проектов верхнего уровня Apache [2].
Основными достоинствами RDD считают отказоустойчивость и ленивые вычисления, благодаря которым возрастает скорость работы с данными, и уменьшается риск потери данных при выходе из строя одного из составляющих кластерного оборудования.
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники
- https://habr.com/ru/post/251507/
- https://www.oreilly.com/library/view/learning-spark/9781449359034/ch03.html