
NVIDIA работает вместе с разработчиками библиотек Apache Spark и RAPIDS для реализации ускорения GPU. Наконец-то в Apache Spark можно проводить обработку данных на GPU. В этой статье поговорим об ускорителе RAPIDS для Spark 3.0, о том как он работает.
На подготовка данных тратится 80% времени
В последнее время GPU используют для обучения моделей машинного обучения (Machine Learning). Однако 80% времени разработчики проводят за подготовкой данных, т.е. задачи находятся в процессе ETL (extract, transform, load). Для этого и применяется Apache Spark. Но, к сожалению, Spark 2.x не знает о существовании никаких GPU, поэтому подготовка данных осуществляется на CPU. Но возникает закономерный вопрос: “Почему не производить обработку данных на графическом ускорителе (особенно с учетом постоянного увеличения размера)?” Это пытается преодолеть ускоритель RAPIDS.
Ускоритель RAPIDS для Apache Spark 3.0
RAPIDS — это набор открытых библиотек и API для выполнения конвейеров данных полностью на GPU. Он разработан на основе CUDA и UCX. Конкретно Spark RAPIDS позволяет использовать преимущества параллелизма GPU и высокоскоростной памяти без изменений в коде. Он работает с Spark SQL, DataFrame API, а также с новой реализацией Spark shuffle.
RAPIDS и DataFrame
RAPIDS обрабатывает DataFrame’ы на основе структур данных Apache Arrow. Колоночные структуры данных, которые предоставляет Arrow, оптимизированные под выполнение как на CPU, так и на GPU, обрабатываются порциями (батчами, batch), поэтому скорость чтения, записи и запросов повышается в разы.

Когда выполняется запрос в Spark, он проходит следующие стадии:
- создается логический план;
- логический план преобразуется в физический план с помощью оптимизатора запросов Catalyst;
- генерируется код;
- выполняются задачи в кластере.
С использованием ускорителя RAPIDS оптимизатор запросов находит в плане запросов операторы, которые могут быть ускорены через RAPIDS API, обычно с помощью прямого отображения. При выполнении плана запросов он также составляет расписание для этих операторов в GPU для кластера. В отличие от выполнения физического плана на CPU, когда DataFrame преобразуется в RDD и обычно обрабатывается только одна строка за раз, RAPIDS производит обработку колоночных батчей в большинстве случаев.
RAPIDS и Spark shuffles
Сортировка, группировка, соединение данных по значению предполагает некоторые этапы перемещения данных между портициями при создании нового DataFrame из уже созданного. Этот процесс называется перетасовкой, или shuffle.
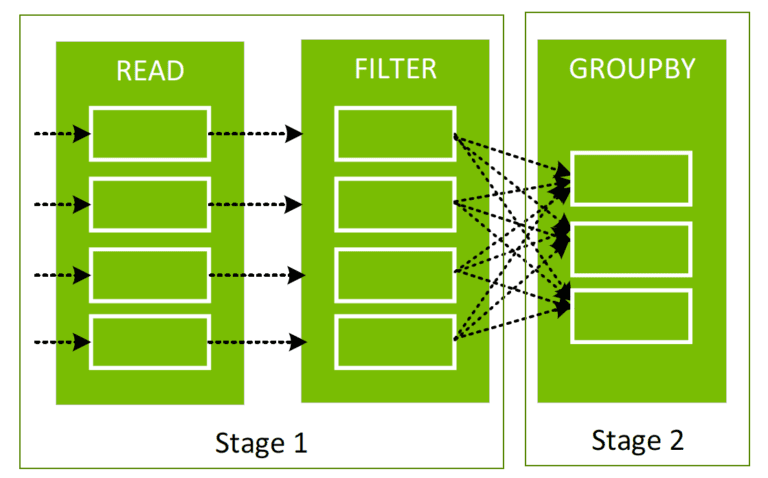
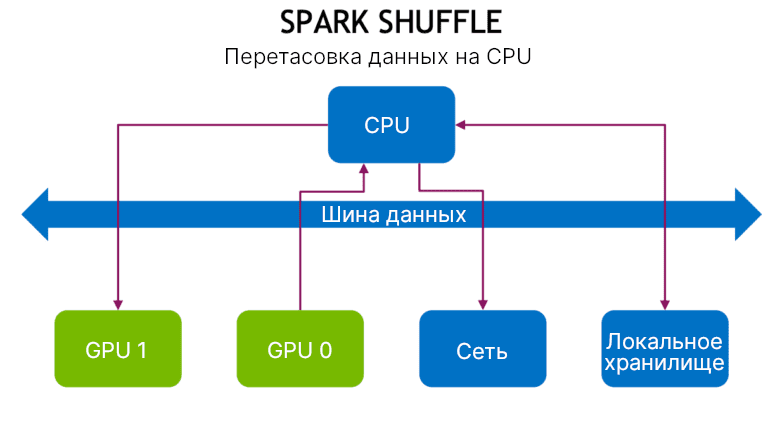
Сначала происходит запись данных на локальный диск и затем данные перемещаются по сети в портиции на другие CPU или GPU. Перетасовка — это дорогая операция для процессора, оперативной памяти, памяти диска, сети.
Поэтому используется новая реализации перетасовки данных на основе библиотеки UCX (Unified Communication X). Она использует некий набор абстрактных коммуникационных примитивов, что более эффективно использует ресурсы (GPU, RDMA, TCP, разделяемую память, передачу по сети).
В новой реализации перетасовки настолько много данных насколько возможно сначала кэшируются в GPU. Это означает, что перетасовки данных для следующей задачи на GPU не будет. Далее, если GPU находятся на том же самом узле и соединенные по NVIDIA NVLink, то данные перемещаются с скоростью 300 Гб/cек. Если GPU находятся на разных узлах, то RDMA (удалённый прямой доступ к памяти) позволяет им общаться напрямую между друг другом через узлы с скоростью 100 Гб/сек. Каждый из этих случаев позволяет избежать застаивания на шине данных и процессоре.
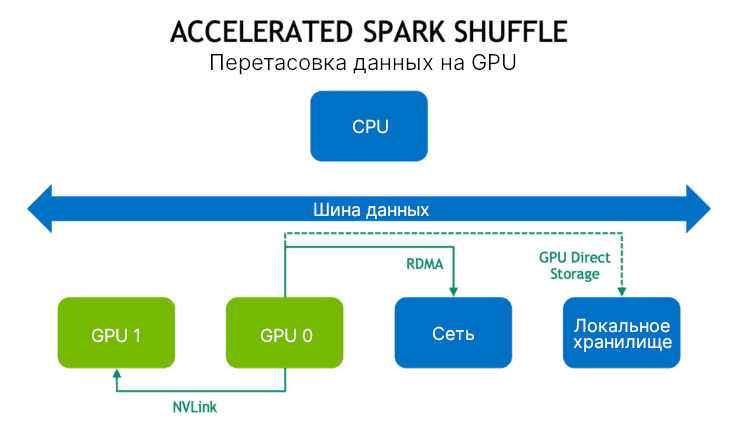
Если не все данные не могут быть кэшированы локально, то сначала они записываются в память хоста и затем распределяется на диске, когда они исчерпались. Доступ к данным из памяти хоста также позволяет избежать застаивания на шине данных и процессоре благодаря RDMA.
Управляйте GPU из Spark
В Apache Spark 3.0 вы можете планировать, когда выполнять операции на GPU. Можно указать количество GPU требуется для задачи. Spark передает эти запросы на ресурсы менеджеру кластера, Kubernetes, YARN или приложению. Также можно узнать, какие GPU были переданы менеджеру кластера. Это упрощает выполнение ML-приложений, которым нужны GPU.
Например, пользователь передает приложение с конфигурационными скриптами об использовании GPU. Spark запускает драйвер, который в свою очередь передает скрипт менеджеру кластера, для запроса контейнер с заданным количеством ресурсов и GPU. Менеджер кластеров возвращает контейнер. Spark запускает контейнер. Исполнитель при запуске выполняет скрипт. Затем Spark передает информацию обратно в драйвер, который на основании информации в скрипте, планирует выполнение задач в GPU.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
21 сентября, 2026
Продолжительность
22 ак.часов
Стоимость обучения
51 200 руб.
О том, как настраивать Apache Spark на выполнение задач в GPU вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков

