YARN — это фреймворк управления ресурсами в Apache Spark, другими словами, это почти операционная система на кластерном уровне.
Основные Компоненты
В основе YAYN лежит разделение управление ресурсами между ResourceManager (Менеджер ресурсов) и приложениями ApplicationMaster (Мастер приложения). Приложение — это то, что ставится на планировщике в YARN кластере; это есть либо одиночное задание, либо граф заданий (DAG). Здесь под заданиями имеется в виду задание Spark, запрос в Hive или любая другая похожая конструкция).
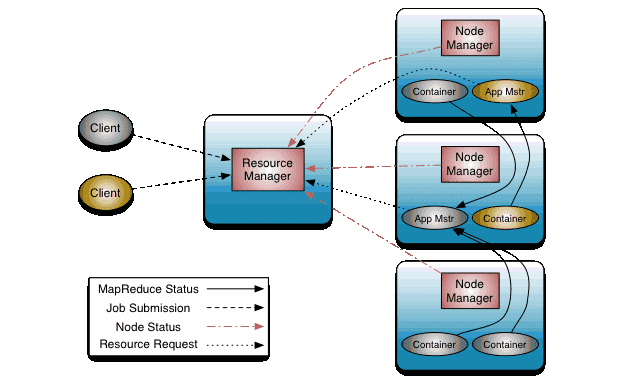
Менеджер ресурсов распределяет ресурсы между всеми приложениями. NodeManager (Мастер узла) — это агент, ответственный за контейнеры, мониторинг, использование ресурсов (CPU, память, сеть), а также отчитывается об о всем этом перед Менеджером ресурсов.
Приложение
На самом высоком уровне находится приложение Spark. Приложение может использоваться для одиночного задания, интерактивной сессии со множеством заданий или сервера, на который постоянно поступают запросы. Приложение Spark может состоять из множество задач Map и Reduce. С другой стороны, приложение YARN предназначен для планирования и размещения ресурсов. Приложение Spark, переданное в YARN, отправляется в приложение YARN.
Драйвер Spark
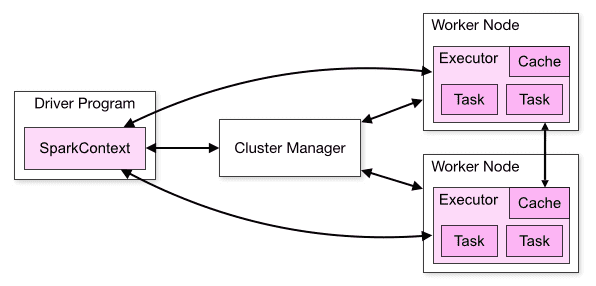
Приложения Spark координируются объектом SparkContext (или SparkSession) в основной программе, которая называется драйвером. Поэтому часть кода, в котором инициализируется SparkContext, и есть драйвер, который управляет потоком заданий (job), планирует задачи (task) и доступен в течение всего времени работы приложения (драйвер должен следить и принимать входящие вызовы от своих исполнителей на протяжении всего своего жизненного цикла).
Клиент YARN
Программа, которая передает приложение в YARN, называется клиентом YARN. Расположение драйвера относительно клиента и Мастера приложений определяет режим развертывания, в котором работает приложение Spark: клиентский режим или кластерный режим.
В клиентском режиме драйвер выполняется на стороне клиента YARN. Поэтому он не управляется как часть кластера. Кроме того, клиент не может выйти до завершения работы приложения.
В кластерном режиме выполняется в Мастере приложений, который в свою очередь выполняется внутри находящегося в кластере контейнера. А клиент YARN только получает статус работы от Мастера приложений. В этом случае клиент может выйти после передачи приложения.
Исполнитель и контейнер
Каждый исполнитель Spark выполняется в контейнере YARN. Поэтому приложение Spark занимает ресурсы в течение всего своего времени. Такая процедура отличается MapReduce, где постоянно возвращаются ресурсы в конце каждой задачи и снова выделяются в начале следующей задачи.
Настройка
Примерно понимая вышеизложенное, можно настроить YARN в Apache Spark для своих нужд.
Рассмотрим некоторые конфигурации:
yarn.nodemanager.resource.memory-mbопределяет объем физической памяти, который может быть выделен для контейнеров в узле. Это значение должно быть меньше доступной памяти на узле.yarn.scheduler.minimum-allocation-mbминимальная выделенная память для каждого запроса контейнера в Менеджере ресурсов. С этим значением можно понять, как разделять ресурсы узла в контейнере. Запросы с количеством памяти ниже этого значения вызовут исключениеInvalidResourceRequestException.yarn.scheduler.maximum-allocation-mb— максимальная выделенная память для каждого запроса контейнера в Менеджере ресурсов. Запросы с количеством памяти выше этого значения вызовут исключениеInvalidResourceRequestException.
Приведенные выше конфигурации означают, что Менеджер ресурсов может выделять память контейнерам только с шагом minimum-allocation-mb и не превышать maximum-allocation-mb. Кроме того, общая выделенная память узла не должна превышать nodemanager.resource.memory-mb.
Теперь перейдем к определенным конфигурациям Spark. В частности, мы рассмотрим эти конфигурации с точки зрения выполнения задания Apache Spark в YARN.
spark.executor.memory. Поскольку каждый исполнитель работает как контейнер YARN, он связан с перечисленными выше настройками. Исполнители будут использовать выделение памяти, равное данному значению. По сути, запрос на память равен суммеspark.executor.memory + spark.executor.memoryOverhead.spark.driver.memory— объем памяти, необходимой для драйвера. А поскольку драйвер управляется YARN’ом, это свойство определяет объем памяти, доступной ApplicationMaster. В клиентском режиме не может быть задан через SparkConf, только через командную строку.
Читайте также:
- Как работает SparkSQL изнутри и причем здесь Catalyst
- 3 метода параллельной обработки данных в Spark
- 3 совета по ускорению Apache Spark