
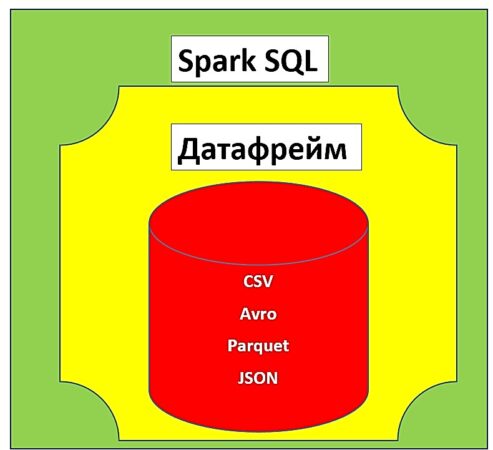
Спарк SQL — это модуль фреймворка Spark для структурированной обработки распределенных данных, позволяющий выполнять запросы на языке SQL (Structured Query Language). Спарк SQL использует датафреймы (dataframe) для работы с данными. Датафрейм — это структура данных, представляющая собой таблицу c данными, упорядоченными по именованным столбцам. Спарк SQL поддерживает загрузку данных из различных внешних источников (например, Hive, JSON, Avro,) для формирования датафреймов [1].
Что такое Spark SQL: основные свойства и особенности архитектуры
Спарк SQL — это компонент фреймворка Apache Spark для структурированной (упорядоченной) обработки данных. Внутренний механизм вычислений и преобразований в Spark SQL не зависит от языка программирования, поэтому разработчик имеет возможность самостоятельно определять интерфейс языка программирования (например, Java, Python, Scala или R). Спарк SQL имеет следующий свойства:
- интеграция — Спарк SQL может запрашивать данные с помощью SQL-запросов из различных СУБД (например, MySQL, MS SQL Server, Oracle, Hive) в виде распределенной коллекции данных (Resilient Distributed Dataset, RDD);
- универсальный доступ к данным — работа со всеми источниками данных происходит по одной и той же схеме, так как доступ к данным обеспечивается посредством механизма SQL-запросов;
- источники данных — Спарк SQL поддерживает работу с различными файловыми источниками (например, JSON, CSV, Parquet). Существует также возможность смешивать данные из различных источников.
В архитектуру Спарк SQL входят следующие составляющие:
- Программный API (Application Program Interface) — Спарк SQL поддерживает работу в таких языках программирования, как Java, Python, Scala и R, предоставляя методы и функции для работы с данными. Также имеется возможность работы с Hive благодаря поддержке SQL-подобного диалекта HiveQL и предоставляя доступ к хранилищу Hive.
- SchemaRDD — таблица для временного (промежуточного) хранения данных, которая используется для работы с SQL-запросами при разработке приложений на языках Python, Java, Scala или R. SchemaRDD также позволяет задавать необходимые типы данных для создания датафреймов на основе этих данных [1].

Как появился Спарк SQL: краткая история
Работа над Спарк SQL началась в 2009 году. Это было связано с идеей проекта для работы с распределёнными данными — Apache Spark. Предполагалось, что модуль Спарк SQL позволит работать с большими данными посредством SQL-запросов, что сделает ферймворк Spark универсальным средством для обработки Big Data. Автором Спарк SQL является румынско-канадский ученый в области информатики Матей Захария. В 2010 году Спарк SQL был опубликован как модуль Spark для работы с SQL-запросами под лицензией BSD (Berkeley Software Distribution), а в 2013 году передан фонду Apache и переведен на лицензию Apache 2.0. Первая версия Spark SQL 1.0.0 выпущена 15 октября 2012 года. В 2014 году проект Spark принят в число проектов верхнего уровня Apache. Последняя версия Спарк SQL 3.1.0 была выпущена 5 января 2021 года [2].
Начало работы со Spark SQL
Для того, чтобы начать работу со Спарк SQL, необходимо настроить базовую конфигурацию. Для этого нужно импортировать класс SparkSession, который служит точкой входа для работы со Spark. Следующий код на языке Python отвечает за настройку базовой конфигурации Спарк SQL:
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
Для работы с данными через SQL-запросы необходимо создать представление (view) с помощью метода createOrReplaceTempView:
my_table = csv_data.createOrReplaceTempView('my_table')
После создания представления можно работать с ним как SQL-таблицей. Для этого в Spark есть специальный метод sql, который принимает в качестве параметра строку, содержащую SQL-запрос:
sql_table = spark.sql('SELECT * FROM my_table')
При работе с данными можно задавать условие выборки с помощью ключевого слова WHERE. В качестве примера можно рассмотреть выборку твитов, id которых лежит в диапазоне от 1 до 10:
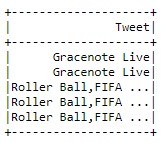
sql_table = spark.sql('SELECT Tweet FROM my_table WHERE id IN (1,10)')
sql_table.show()

Из вышерассмотренного примера, что некоторые данные являются отсутствующими, т.е. имеют null-значения. Чтобы удалить эти пропуски, необходимо использовать метод Spark SQL na.drop(), который их удалит [3]:
sql_table = spark.sql('SELECT Tweet FROM tweets_table WHERE id IN (1,10)').na.drop()
sql_table.show()
Таким образом, благодаря гибкости и интеграции модуля Спарк SQL, фреймворк Apache Spark имеет довольно широкий функционал для работы с Big Data любой структуры. Все это делает Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений.
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники
- https://ru.bmstu.wiki/Spark_SQL
- https://ru.wikipedia.org/wiki/Apache_Spark
- К.Харау, Э.Ковински, П.Венделл, М.Захария. Изучаем Spark: молниеносный анализ данных