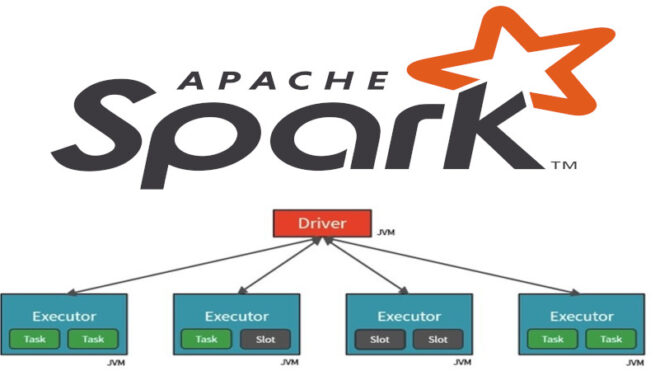
Apache Spark - это мощный фреймворк для обработки больших объемов данных в распределенной среде. Он предоставляет разнообразные инструменты и библиотеки для обработки и анализа данных,...

10 вопросов на знание основ Spark: открытый комплексный тест для начинающих
Чтобы самостоятельное обучение по Spark стало еще интереснее, сегодня мы предлагаем вам комплексный тест на знание основ работы распределенного фреймворка Apache Spark, включая его особенности,...

Что такое параллелизм в Spark
Apache Spark - это мощный фреймворк для обработки больших объемов данных, который предоставляет распределенные вычисления на кластерах. Один из ключевых факторов, влияющих на производительность Spark...

Что такое PageRank и как его реализовать на Spark
Алгоритм PageRank – это один из фундаментальных алгоритмов в области поисковых систем и анализа графов. Он был разработан Ларри Пейджем и Сергеем Брином в начале...

10 вопросов на знание основ работы с фреймворка Spark: открытое комплексное тестирование для начинающих
Чтобы самостоятельное обучение по Spark стало еще интереснее, сегодня мы предлагаем вам простое комплексное тестирование по основам работы распределенного фреймворка Apache Spark, включая его особенности...
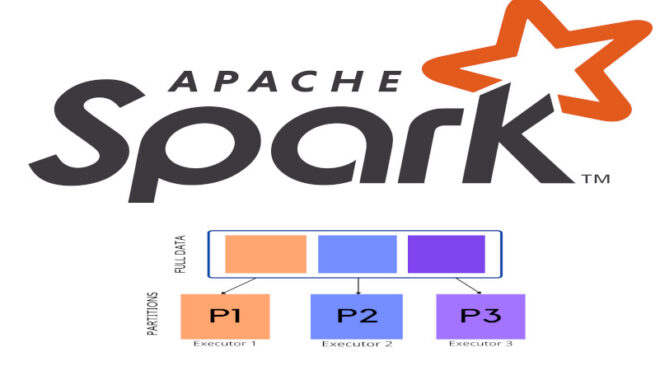
Распределение данных в Spark: как это происходит
Сегодня мы обсудим управление распределением данных во фреймворке Spark. Читайте далее, чтобы узнать больше о том, как данные распределяются в приложениях Spark для работы с...

Тестирование базовых навыков Spark: 10 вопросов для начинающих
Чтобы самостоятельное обучение по Spark стало еще интереснее, сегодня мы предлагаем вам тест по основам работы распределенного фреймворка Apache Spark, включая его особенности, архитектуру, возможности...

Поддерживаемые общие переменные в Apache Spark
В данной статье мы сосредоточимся на общих переменных, которые поддерживаются в Apache Spark. Рассмотрим особенности разных типов общих переменных и их практическое применение в вычислительных...

Как происходит сериализация данных в Apache Spark
В этой статье обсудим важную тему сериализации данных в распределенных приложениях, созданных на базе распределенной фреймворка Apache Spark для работы с Big Data. Читайте далее,...

Тест на знание основ работы Spark: открытый общий комплексный тест для начинающих
Чтобы самостоятельное обучение по Spark стало еще интереснее, сегодня мы предлагаем вам тест по основам работы распределенного фреймворка Apache Spark, включая его особенности, архитектуру, возможности...