Apache Spark SQL поддерживает оконные функции (window functions), которые могут пригодиться для различных задач, например для получения нарастающего значения или скользящей средней. В этой статье рассмотрим применение агрегатных функций с использованием окон.
Оконные функции проводят агрегирование для групп строк
Для примера возьмем датасет iris:
df = spark.read.csv("iris.csv", header=True)
df.show()
"""
+------------+-----------+------------+-----------+-------+
|sepal_length|sepal_width|petal_length|petal_width|species|
+------------+-----------+------------+-----------+-------+
| 5.1| 3.5| 1.4| 0.2| setosa|
| 4.9| 3.0| 1.4| 0.2| setosa|
| 4.7| 3.2| 1.3| 0.2| setosa|
| 4.6| 3.1| 1.5| 0.2| setosa|
| 5.0| 3.6| 1.4| 0.2| setosa|
+------------+-----------+------------+-----------+-------+
"""
Допустим, требуется посчитать максимальное значение какого-либо столбца. Конечно, делается это очень просто:
import pyspark.sql.functions as F
df.select(F.max("sepal_length")).show()
"""
+-----------------+
|max(sepal_length)|
+-----------------+
| 7.9|
+-----------------+
"""
А что если мы хотим добавить это значение в виде отдельного столбца, добавленного к исходному датафрейму? В этом случае нам могут пригодиться оконные функции. Они предназначены для вычисления некоторой группы строк, называемой окном (window). Этим окном может быть вся таблица, или только его часть, например, партиция (partition).
Оконные функции задействуют оператор over. Продемонстрируем это на чистом SQL:
SELECT *, MAX(sepal_length) OVER() as max FROM iris; """ +------------+---+ |sepal_length|max| +------------+---+ | 5.1|7.9| | 4.9|7.9| | 4.7|7.9| | 4.6|7.9| | 5.0|7.9| +------------+---+ """
Если бы мы не добавили OVER, то посчиталось бы одно единственное значение, а так максимальное значение было добавлено к каждой строке.
В Apache Spark, чтобы использовать оконные функции, нужно сначала инициализировать экземпляр класса Window.
from pyspark.sql import Window
w = Window.rowsBetween(Window.currentRow, Window.unboundedFollowing)
max_sepal_length = F.max("sepal_length").over(w).alias("max")
df.select("sepal_length", max_sepal_length).show()
Здесь мы указали границы окна: от текущей строки (currentRow) до конца (unboundedFollowing). В большинстве случае и не нужно считать всю таблицу. Границы устанавливаются точно такие же как в SQL — rows_between и range_between.
Вычисление максимального значения по группам (партициям)
В исходном датасете цветки разбиты по видам. Мы можем найти максимальное значение для каждого вида. Это можно сделать обычной группировкой groupBy. Но что если опять требуется к исходной таблице добавить максимальное значение каждой группы?
Для этого требуется посчитать максимальное в каждой партиции (о партициях тут). SQL-запрос будет выглядеть так:
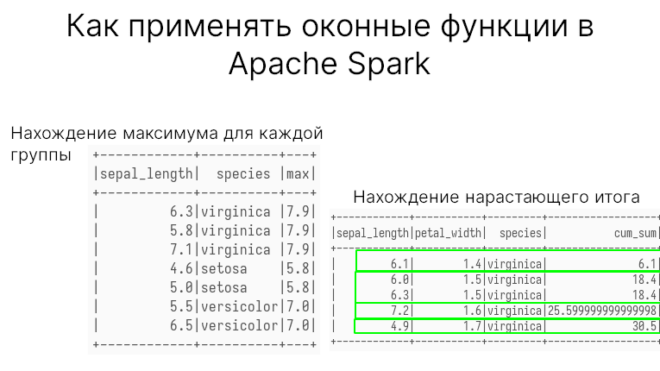
SELECT DISTINCT sepal_length, species, MAX(sepal_length) OVER(PARTITION BY species) as max FROM iris; """ +------------+----------+---+ |sepal_length| species |max| +------------+----------+---+ | 6.3|virginica |7.9| | 5.8|virginica |7.9| | 7.1|virginica |7.9| | 4.6|setosa |5.8| | 5.0|setosa |5.8| | 5.5|versicolor|7.0| | 6.5|versicolor|7.0| +------------+----------+---+ """
Как видим, для каждого вида свое максимальное значение. То же самое, но в Spark SQL:
max_sepal_length = F.max("sepal_length").over(w).alias("max")
df.select("sepal_length", "species", max_sepal_length)
Помимо max можно использовать следующие агрегатные функции:
min— минимум;sum— сумма;avgилиmean— среднее;stddevилиstddev_samp— стандартное отклонение по выборке;stddev_pop— стандартное отклонение по генеральной выборке;varianceилиvar_samp— дисперсия выборки;var_pop— дисперсия генеральной выборки;first— все значения примут первое значение строки (в т.ч. внутри партиции);last— все значения примут последнее значение строки (в т.ч. внутри партиции).
Использование ORDER BY создает кумуляту в Apache Spark
Окна поддерживают сортировку ORDER BY. Для каждого уникального значения внутри сортировки можно применить агрегатную функцию. Применение суммы в качестве агрегатной функции даст кумуляту, т.е. нарастающий итог.
Запрос SQL будет выглядеть так:
SELECT sepal_length, petal_width, species, SUM(sepal_length) OVER(PARTITION BY species ORDER BY petal_width) as cum_sum FROM iris;
Запрос в Apache Spark так:
w = Window.partitionBy("species").orderBy("petal_width")
cum_sum = F.sum("sepal_length").over(w).alias("cum_sum")
df.select("sepal_length", "petal_width", "species", cum_sum)

petal_widthЗдесь можно увидеть, как растет сумма sepal_length с ростом petal_width.
Код курса
SPOT
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
В следующей статье поговорим о построении скользящей средней с помощью оконных функций в Apache Spark. А о том, как применять оконные функции на примерах из Data Science вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и IT-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных
- Машинное обучение
- Графовые алгоритмы
- Потоковая обработка
- Основы Apache Spark для разработчиков

