
В прошлый раз мы говорили про файловые системы, с которыми работает фреймворк Apache Spark. Сегодня рассмотрим, как Spark SQL работает с данными в JSON и в Apache Hive, разобрав примеры создания и извлечения больших данных.
2 самых популярных источника структурированных данных в Spark SQL
Spark SQL поддерживает множество различных источников данных (Pig, Impala, Hive, JSON). Благодаря модулю SQL он позволяет извлекать данные из этих источников с помощью стандартного механизма ANSI SQL-запросов. Самыми распространенными источниками данных, с которыми работает Spark SQL являются следующие:
• Apache Hive;
• JSON.
Каждый из них мы подробнее рассмотрим далее.
Apache Hive
Apache Hive – это система управления базами (СУБД) на основе платформы Hadoop. Hive напрямую работает с файловой системой HDFS и использует язык подобный языку SQL с собственным диалектом HQL (Hive Query Language). Благодаря модулю Spark SQL можно загружать таблицы из Hive напрямую, формируя набор записей RDD:
from pyspark.sql import HiveContext hive_Ctx = HiveContext(sc) rows = hive_Ctx.sql( " SELECT name, age FROM employees ") ### Spark RDD
В Hive можно также работать с данными, загруженными из внешних источников c помощью специальных методов фреймворка Spark. Для этого с помощью метода registerDataFrameAsTable() формируется датафрейм, который можно анализировать через диалект HQL:
data = spark.read.option('header','True').csv('my_tweets.csv')
hive_context = HiveContext(sc)
hive_context.registerDataFrameAsTable(data,'tweets')
table = hive_context.sql(' SELECT DISTINCT Tweet FROM tweets WHERE id IN (1,10) ') ### Spark dataframe
table.show()

Таким образом, запрос на диалекте HQL очень похож на стандартный SQL-запрос, что упрощает работу с данными Hive и делает ее интуитивно понятной.
JSON
JSON (JavaScript Object Notation) – это текстовый источник данных, структурой которого является пара ключ/значение. Справедливости ради стоит отметить, что данные в формате JSON считаются полуструктурированными, т.к. поля JSON-документа могут варьироваться для разных записей. Тем не менее, поскольку этот формат данных очень распространен в области Big Data Science, мы рассмотрим, как Apache Spark работает с JSON-файлами. Spark может считывать данные из JSON-источника, регистрировать их как таблицу с помощью метода registerTempTable() и возвращать в форме записей при помощи запроса SQL (или диалекта HQL):
tweets = hive_context.read.option("multiline","true").json("tweets_json.json")
tweets.registerTempTable("tweets")
results = hive_context.sql(" SELECT * FROM tweets ")
results.show()

Как видно из рисунка, этот запрос вернул все данные, связанные с атрибутом «user». При необходимости мы можем также получать конкретные данные, например, имя пользователя или его адрес:
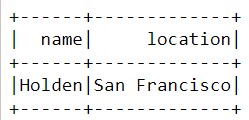
results = hive_context.sql(" SELECT user.name, user.location FROM tweets ")
results.show()
Таким образом, можно быстро и просто извлекать нужные данные из JSON-файлов.
Подводя итог возможностям работы Spark с полуструктурированными и структурированными источниками данных, отметим, что этот Big Data фреймворк позволяет Data Scientist’у анализировать большие данные в удобном и понятном виде. При этом можно самостоятельно выбирать необходимые данные для дальнейшей работы с ними. В следующей статье мы поговорим про числовые операции над наборами RDD в Spark.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.

