
Хадуп – это набор библиотек, утилит и фреймворков для разработки и выполнения распределенных приложений, работающих в кластерах. Hadoop является свободно распространяемым проектом фонда Apache и основной экосистемой в области Big Data.
Что входит в Hadoop: основные компоненты
Apache Hadoop — это экосистема из связанных проектов и технологий, которая считается основополагающей технологией работы с большими данными.
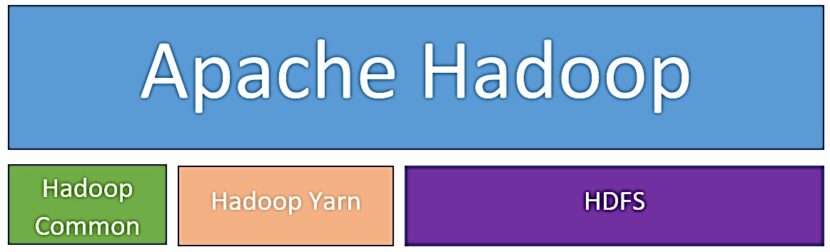
Система Хадуп включает в себя следующие элементы:
- Hadoop Common — это набор библиотек для управления файловыми системами. Hadoop Common также включает в себя сценарии (например, dfs-сценарий) управления распределенной обработкой больших данных, для выполнения которых был создан упрощенный интерпретатор командной строки (File System shell, FS shell), который запускается прямо из оболочки операционной системы.
- HDFS (Hadoop Distributed File System) — это файловая система, предназначенная для хранения файлов больших размеров, которые поблочно распределены между узлами вычислительного кластера. Все блоки в HDFS имеют одинаковый размер, и каждый блок может быть размещен на нескольких узлах вычислительного кластера. Отказоустойчивость файловой системы обеспечивается благодаря репликации (копированием данных между узлами кластера). Файлы в HDFS записываются лишь однажды (без возможности модификации). Организация файлов иерархическая: есть корневой каталог, а также поддерживается создание вложенных каталогов. В одном каталоге могут располагаться как файлы, так и другие каталоги.
- YARN (Yet Another Resource Negotiator) — это модуль, который отвечает за управление ресурсами в кластере и планирование заданий. YARN способен обеспечивать возможность параллельного выполнения нескольких задач. Он также выступает интерфейсом между аппаратными ресурсами кластера и приложениями, использующими мощности этого кластера для вычислительной обработки.
Как появился и развивался Hadoop: краткая история
Разработка Хадуп началась в начале 2005 года Дугом Каттингом с целью построения программной инфраструктуры распределенных вычислений для проекта Nutch (поисковая машина на языке JAVA). В конце 2005 года к разработке Хадуп присоединился Майк Кафарелла. И уже в январе 2006 года корпорация Yahoo предложила Каттингу возглавить команду разработки инфраструктуры распределенных вычислений. Таким образом, Хадуп выделяется в отдельный проект. В феврале 2008 года Yahoo запустила поисковую кластерную машину под управлением системы Хадуп. В январе 2008 года Хадуп становится проектом верхнего уровня системы проектов Apache Software Foundation. В апреле 2008 года система Хадуп дала первый рекордный результат: 1Тбайт данных был обработан за 209 секунд. С этого момента Hadoop начали внедрять в свои проекты такие компании, как Facebook, The New York Times и Last.fm. Также проводится адаптация для запуска Hadoop в облачном сервисе Amazon EC2. В апреле 2010 года компания Google предоставила Apache Software Foundation права на использование технологии распределенных вычислений MapReduce. Осенью 2013 года выходит версия Hadoop 2.0, выходящая за пределы технологии MapReduce благодаря реализации модуля YARN.
Таким образом, благодаря быстрой распределенной работе с большими данными, а также контролю распределения ресурсов в кластере, Hadoop является универсальным решением для организации обработки больших массивов данных. Именно поэтому Hadoop является неотъемлемой частью технологий и фреймворков (например, Spark, Hive, Pig) для работы с большими данными (Big Data), включая различные направления Data Science, такие как подготовку и анализ данных, а также аналитические системы на базе алгоритмов машинного обучения (Machine Learning).
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники