
В прошлый раз мы говорили про механизм сериализации данных в распределенном фреймворке Apache Spark. Сегодня поговорим про управление распределением данных в Spark. Читайте далее про особенности распределения данных в Spark-приложениях для работы с Big Data в параллельной (распределенной) среде.
Особенности распределения данных в Apache Spark
Распределение в Spark — это размещение данных в кластере таким образом, чтобы максимально уменьшить сетевой трафик (объем передаваемой информации через сеть) и, тем самым, увеличить производительность Spark-приложения. Уменьшение сетевого трафика в Spark достигается благодаря уменьшению взаимодействий между узлами в вычислительном кластере путем распределения наборов RDD (Resilient Distributed Dataset) по разделам. Стоит отметить, что распределение данных полезно только в том случае, когда наборы данных многократно используются приложением, то есть совершается большое количество попыток сетевых соединений в кластере [1].
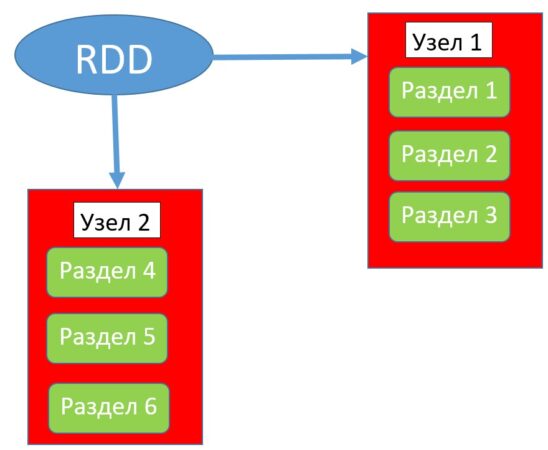
При распределении данных стоит учитывать количество создаваемых для распределения разделов, так как при создании большого их количества может также увеличиться количество взаимодействий между узлами, а значит и сетевой трафик, что может привести к снижению производительности приложения.
Как начать распределение данных в Spark: несколько практических примеров
Для того, чтобы начать работать с распределением данных, необходимо настроить базовую конфигурацию среды выполнения (для запуска Spark-сессии). Следующий код на языке Python задает базовую конфигурацию среды Spark и запускает Spark-сессию:
from pyspark.sql import SparkSession
# В качестве примера используется порт по умолчанию (local)
conf = pyspark.SparkConf().setAppName('appName').setMaster('local')
# Развертывание среды Spark с указанными настройками
sc = pyspark.SparkContext(conf=conf)
# Запуск Spark-сессии
spark = SparkSession(sc)
В качестве объекта распределения фреймворк Spark использует данные наборов RDD, поэтому для осуществления распределения необходимо преобразовывать исходные данные в набор RDD. Следующий код на языке Python отвечает за создание датафрейма и преобразование его в набор RDD c помощью функции rdd:
my_schema=StructType([StructField('id',IntegerType(),True),\
StructField('name',StringType(),True),\
StructField('age',IntegerType(),True),\
StructField('country',StringType(),True),])
data_2=spark.createDataFrame([(1,'Alice',25,'USA'),(2,'John',45,'Canada'),(3,'Michael',37,'USA'),
(4,'John',50,'Canada'),
(5,'Emmet',25,'Canada')],\
['id','name','age','country'],my_schema)
data_2. rdd
По умолчанию нераспределенные данные в Spark имеют один раздел (partition). Для распределения данных необходимо создать больше одного раздела, то есть перераспределить набор данных. За перераспределение данных отвечает метод repartition(), который в качестве параметра принимает число разделов для перераспределения [2]:
data_2.rdd.repartition(10)
После использования метода repartition() может возникнуть «перетасовка» данных, так как при каждом обращении данные случайным образом перераспределяются по разделам, и для того, чтобы найти необходимый раздел, приходится инициировать дополнительные соединения между узлами, что может привести к снижению производительности Spark-приложения. Чтобы избежать этого, необходимо сформировать «устойчивые» разделы, которые будут хранить в себе одинаковые наборы данных при каждом обращении к ним. Для того, чтобы сделать разделы «устойчивыми», необходимо использовать метод persist() при распределении данных [2]:
data_2.rdd.repartition(10).persist()
Таким образом, благодаря механизму распределения данных, фреймворк Spark способен обеспечивать весьма высокую производительность распределенных приложений и задействовать при этом минимум вычислительных мощностей. Это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика распределенных Big Data приложений. В следующей статье мы поговорим про особенности взаимодействия Spark с реляционными СУБД.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники
- К.Харау, Э.Ковински, П.Венделл, М.Захария. Изучаем Spark: молниеносный анализ данных
- https://spark.apache.org/docs/2.4.0/api/python/pyspark.sql.html?highlight=partition

