Сегодня мы обсудим управление распределением данных во фреймворке Spark. Читайте далее, чтобы узнать больше о том, как данные распределяются в приложениях Spark для работы с большими объемами данных в распределенной среде.
Для чего нужно распределение данных в Spark
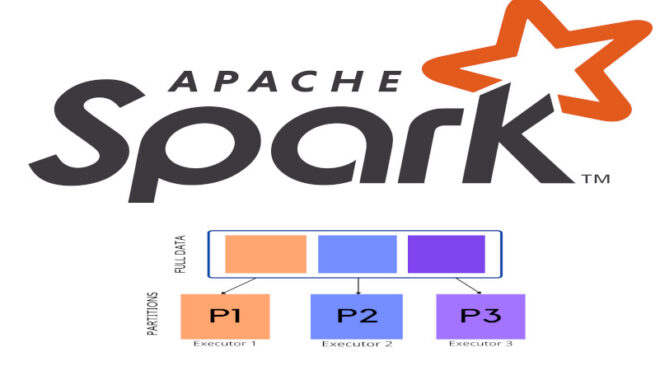
Распределение данных во фреймворке Spark означает размещение данных в кластере таким образом, чтобы минимизировать объем сетевого трафика и, следовательно, повысить производительность Spark-приложения. В Spark снижение сетевого трафика достигается путем уменьшения взаимодействий между узлами в вычислительном кластере с помощью распределения наборов RDD (Resilient Distributed Dataset) по разделам. Важно отметить, что распределение данных полезно только в случае многократного использования наборов данных приложением, то есть когда в кластере происходит большое количество сетевых соединений.
Особенности распределения данных во фреймворке Spark: несколько практических примеров
Одним из основных способов распределения данных во фреймворке Spark является использование распределенных коллекций данных, называемых RDD (Resilient Distributed Datasets). RDD — это неизменяемая коллекция объектов, которая может быть разделена на несколько частей и обработана параллельно. Распределенные коллекции данных могут быть созданы из локальных коллекций или загружены из внешних источников данных. Вот пример создания RDD из локальной коллекции данных в Spark:
from pyspark import SparkContext
# Создание SparkContext
sc = SparkContext("local", "DataDistributionExample")
# Создание RDD из локальной коллекции данных
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
# Вывод элементов RDD
print(rdd.collect())
В этом примере мы создаем SparkContext, который является точкой входа для любых операций Spark, и затем создаем RDD из локальной коллекции данных с помощью метода parallelize(). Метод collect() используется для получения всех элементов RDD.
Spark также предоставляет возможность чтения и записи данных из различных внешних источников, таких как файлы CSV, JSON, паркеты и многое другое. Это особенно полезно при работе с большими объемами данных, которые не помещаются в память одной машины. Рассмотрим пример чтения данных из CSV-файла и создания RDD в Spark:
from pyspark.sql import SparkSession
# Создание SparkSession
spark = SparkSession.builder.appName("DataDistributionExample").getOrCreate()
# Чтение данных из CSV-файла
df = spark.read.csv("data.csv", header=True, inferSchema=True)
# Преобразование DataFrame в RDD
rdd = df.rdd
# Вывод элементов RDD
print(rdd.collect())
В этом примере мы используем SparkSession для создания сеанса Spark и чтения данных из CSV-файла «data.csv» с помощью метода read.csv(). Мы также указываем, что файл содержит заголовок и требуется автоматическое определение схемы данных (header=True, inferSchema=True). Затем мы преобразуем DataFrame в RDD с помощью атрибута rdd.
Таким образом, Apache Spark предоставляет мощные инструменты для обработки и анализа больших объемов данных, распределяя их на кластере для параллельной обработки. Также благодаря механизму распределения данных, фреймворк Spark способен обеспечивать весьма высокую производительность распределенных приложений и задействовать при этом минимум вычислительных мощностей. Это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика распределенных Big Data приложений.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
22 сентября, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Разработка и внедерение ML-решений
- Графовые алгоритмы. Бизнес-приложения
Источники
- https://spark.apache.org/documentation.html
- К.Харау, Э.Ковински, П.Венделл, М.Захария. Изучаем Spark: молниеносный анализ данных

