
В прошлой статье мы говорили об ускорителе RAPIDS для Apache Spark. Сегодня рассмотрим, что появилось в версии RAPIDS 21.10 (релиз за январь) и 22.02 (релиз за февраль). Также в статье приведена оценка производительности выполнения запросов по сравнению с выполнением на CPU.
Ускоренный ускоритель RAPIDS для Apache Spark
RAPIDS для Apache Spark растет быстрым темпом как в функциональности, так и в производительности. Для оценки производительности можно измерить производительность основных операторов, которые используется для обработки и анализа данных.
Для тестирования использовались следующие запросы:
countDistinctподсчет уникальных значений;windowоконная функции;intersectнахождение пересечения;crossJoinсоединения cross-join.
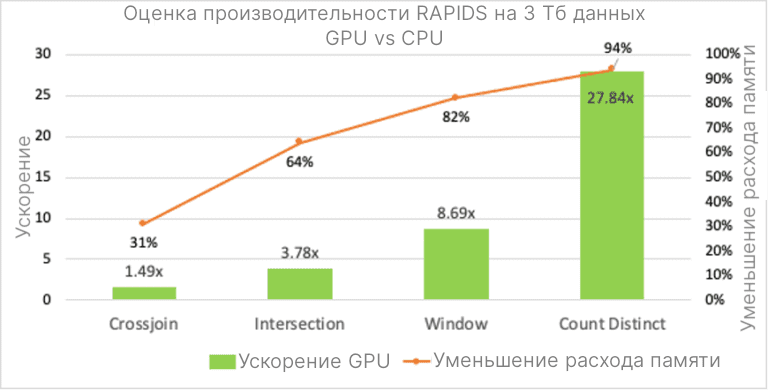
Эти запросы выполнялись в Google Cloud Platform (GCP) с 2xT4 GPU, каждый из которых имеет 1024 Гб памяти. Датасет был размером 3 Тб с различными типами данных. Больше информации можно посмотреть в репозитории spark-rapids-examples. Результаты производительности этих 4 запросов можно посмотреть на рисунке ниже. Как видим, скорость повышается в 1.5 раза для операции соединения и в 27 раз для подсчета уникальных значений по сравнению с выполнением на CPU. При этом наблюдается значительное снижение расходов на память. Значения могут варьироваться в зависимости от компьютера и сети.
Новая функциональность
Версия RAPIDS 22.02 поддерживает Spark 3.2.1 и CUDA 11.x. В этом релизе основной фокус был на расширение операций ввода-вывода, обработки вложенных данных и возможностей машинного обучения (Machine Learning). Ускоритель RAPIDS 21.10 выпустил новый дополнительный модуль jar (Java ARchieve) для поддержки машинного обучения в Apache Spark.
Данный jar-модуль поддерживает метод главных компонент (Principal Component Analysis), о котором говорили тут. Для ETL-операций jar поддерживает форматы JSON. Добавлена поддержка точности целых чисел до 38 цифр (128 бит) в формате Parquet. Также появилась возможность выполнять операции: HashAggregate, Sort, Join SHJ и Join BHJ — на вложенных данных.
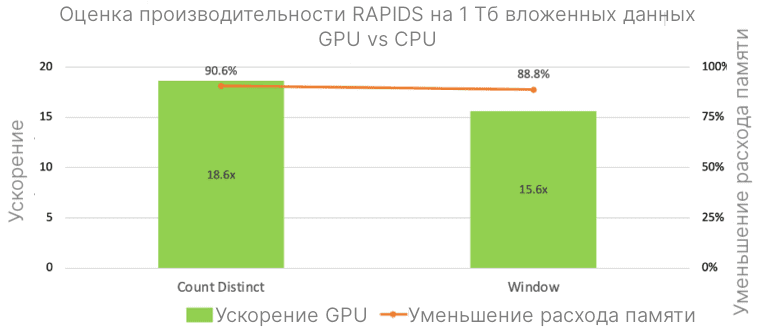
На рисунке ниже показано, как ускорилась обработка вложенных входных типов данных на примере 2 запросов. Также в новую версию RAPIDS были добавлены pos_explode, create_map, функции для регулярных выражений regexp_extract, regexp_replace.
Код курса
MLSP
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Еще больше подробностей о запуске Apache Spark на GPU с помощью библиотек RAPIDS вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков

