В прошлый раз мы говорили про особенности работы алгоритма «один против всех» в Spark. Сегодня поговорим про модель классификации многослойного персептрона в распределенном Big Data фреймворке Apache Spark. Читайте далее про особенности работы алгоритма многослойного персептрона, благодаря которому Apache Spark имеет возможность Big Data анализа и классификации в распределенной среде.
Как работает модель многослойного персептрона: особенности классификации
Многослойный персептрон (Multilayered perceptron) — это класс нейронных сетей прямого распространения (сигналы ошибки модели распространяются от выходов модели к ее входам, в направлении обратном прямому распространению сигналов в обычном режиме работы), состоящий из трех слоев: входного, скрытого и выходного. В качестве активационных функций (определяющих выходные сигналы) нейронов используются логистическая и гиперболический тангенс. Поскольку классификацию можно рассматривать как частный случай регрессии, когда выходная переменная является категориальной, на основе многослойного персептрона можно также строить классификаторы [1].
Работа с алгоритмом многослойного персептрона в Spark: несколько практических примеров
Для того, чтобы начать работу с алгоритмом многослойного персептрона, необходимо настроить базовую конфигурацию, импортировав некоторые классы ml-библитоеки Spark [2]:
from pyspark.ml.classification import MultilayerPerceptronClassifier from pyspark.ml.evaluation import MulticlassClassificationEvaluator
Из импорта видно, что для работы с алгоритмом многослойного персептрона в pyspark используется класс MultilayerPerceptronClassifier, который находится в пакете который находится в пакете pyspark.ml.classification, хранящим в себе классы, описывающие модели классификации и их оценщики. В качестве оценки модели будем использовать оценщик мультиклассовой классификации, за который в pyspark отвечает класс MulticlassClassificationEvaluator. В качестве примера будем использовать встроенный размеченный датасет для мультиклассовой классификации. Для начала необходимо прочитать этот датасет и загрузить его в память [2]:
data = spark.read.format("libsvm")\
.load("C:/spark/spark-3.0.1-bin-hadoop2.7/data/mllib/sample_multiclass_classification_data.txt")

Далее необходимо разбить загруженный датасет на тренирововчную и тестовую выборку случайным образом. За случайное разбиение на выборки отвечает метод randomSplit() [2]:
splits = data.randomSplit([0.6, 0.4], 1234) train = splits[0] test = splits[1]
Так как алгоритм многослойного персептрона работает на основе нейронных сетей, он также имеет слои нейронов: слой на входе, 2 средних (скрытых) слоя нейронов, а также слой нейронов на выходе [2]:
# 4 нейрона на входном слое # 5 нейронов и 4 нейрона на средних слоях (скрытых) # 3 нейрона на выходе layers = [4, 5, 4, 3]
Для построения модели необходимо создать экземпляр класса MultilayerPerceptronClassifier [2]:
trainer = MultilayerPerceptronClassifier(maxIter=100, layers=layers, blockSize=128)
В качестве параметров конструктора у класса MultilayerPerceptronClassifier используется следующие [2]:
maxIter— максимальное количество итераций при обучении модели (эпохи обучения);layers— слои нейронов, из которых состоит обучаемая модель;blockSize— размер блока данных для их преобразований в матрицы (вектора).
Для обучения модели используется метод fit(), а затем формируется датасет с предсказаниями с помощью метода transform() для последующей оценки модели [2]:
model = trainer.fit(train) result = model.transform(test)
В качестве оценщика будем использовать оценщик мультиклассовой классификации MulticlassClassificationEvaluator с метрикой accuracy. За формирование оценки модели отвечает метод evaluate() класса MulticlassClassificationEvaluator [2]:
predictionAndLabels = result.select("prediction", "label")
evaluator = MulticlassClassificationEvaluator(metricName="accuracy")
print("Test set accuracy = " + str(evaluator.evaluate(predictionAndLabels)))
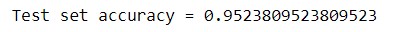
Таким образом, благодаря библиотеке pyspark.ml, существует возможность реализации машинного обучения в распределенной среде Spark. Все это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений.
Код курса
GRAS
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Разработка и внедерение ML-решений
- Графовые алгоритмы. Бизнес-приложения
Источники
- https://wiki.loginom.ru/articles/multilayered-perceptron.html
- https://spark.apache.org/docs/latest/ml-classification-regression.html#multilayer-perceptron-classifier

