
В прошлый раз мы говорили про деревья решений в Spark. Сегодня поговорим про алгоритм мультиклассовой классификации «Один против всех». Читайте далее про алгоритм «Один против всех», благодаря которому Apache Spark имеет возможность Big Data анализа и классификации в распределенной среде.
Как работает мультиклассовая классификация и алгоритм «один против остальных» в Spark
Мультиклассовая классификация — это задача классифицирования примеров в один из трех или более классов. Одной из наиболее известных техник мультиклассовой классификации является техника трансформации в бинарную классификацию. Эта техника преобразует задачу мультиклассовой классификации в несколько бинарных классификаций. Один из видов этой техники является алгоритм «Один против всех».
Алгоритм «Один против всех» (One vs all или One vs Rest) — это модель, которая предоставляет путь решения бинарной классификации из нескольких возможных решений. В течение обучения модель проходит через последовательность бинарных классификаторов (по одному бинарному классификатору для каждого возможного выхода), тренируя каждый их них отвечать на отдельный классификационный вопрос [1].
Работа с алгоритмом One-vs-Rest в Spark: несколько практических примеров
Для того, чтобы начать работы с алгоритмом One-vs-Rest, необходимо настроить базовую конфигурацию, импортировав некоторые классы ml-библитоеки Spark:
from pyspark.ml.classification import LogisticRegression, OneVsRest from pyspark.ml.evaluation import MulticlassClassificationEvaluator
Как видно из импорта, для работы с алгоритмом One-vs-Rest, в pyspark используется класс OneVsRest, который находится в пакете pyspark.ml.classification. В качестве оценки модели будем использовать оценщик мультиклассовой классификации, за который в pyspark отвечает класс MulticlassClassificationEvaluator. В качестве примера будем использовать встроенный размеченный датасет для мультиклассовой классификации. В первую очередь необходимо прочитать с помощью pyspark [2]:
inputData = spark.read.format("libsvm") \
.load("C:/spark/spark-3.0.1-bin-hadoop2.7/data/mllib/sample_multiclass_classification_data.txt")

Далее необходимо случайно разбить наш датасет на тренировочную и тестовую выборки с помощью метода randomSplit() [2]:
(train, test) = inputData.randomSplit([0.8, 0.2])
В качестве базового классификатора будем использовать логистическую регрессию [2]:
lr = LogisticRegression(maxIter=10, tol=1E-6, fitIntercept=True)
Затем применим модель One-vs-Rest, указав в качестве базового классификатора нашу логистическую регрессию [2]:
ovr = OneVsRest(classifier=lr)
Для того, чтобы обучить модель One-vs-Rest используется метод fit(), а затем с помощью метода transform() необходимо сформировать датасет с предсказаниями [2]:
ovrModel = ovr.fit(train) predictions = ovrModel.transform(test)
Для оценки модели необходимо создать экземпляр класса MulticlassClassificationEvaluator, а затем вызвать у этого экземпляра метод evaluate() для получения точности модели [2]:
evaluator = MulticlassClassificationEvaluator(metricName="accuracy")
accuracy = evaluator.evaluate(predictions)
print("Test Error = %g" % (1.0 - accuracy))
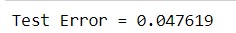
Таким образом, благодаря библиотеке pyspark.ml, существует возможность реализации машинного обучения в распределенной среде Spark. Все это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений.
Код курса
GRAF
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Разработка и внедерение ML-решений
- Графовые алгоритмы. Бизнес-приложения
Источники

