
В прошлой статье мы говорили про работу с числовыми данными в наборах RDD. Сегодня поговорим о том, что такое логистическая регрессия и как с помощью нее сделать прогнозный анализ в Pyspark.
Как работает логистическая регрессия в Spark: особенности прогноза
Логистическая регрессия — это статистическая модель, которая используется в машинном обучении для прогнозирования вероятности возникновения некоторого события путем построения логистической функции и сравнения этого события с кривой этой функции. В результате формируется ответ в виде вероятности бинарного события: 0 и 1, где 0 — событие не произошло, 1 — событие произошло [1].
Работа с логистической регрессией в Spark: несколько практических примеров
Для того, чтобы начать работу по прогнозу данных, необходимо настроить базовую конфигурацию, импортировав некоторые классы библиотек Spark MLlib и Spark SQL:
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *
В качестве датасета будем использовать данные контроля качества пищевых продуктов по городу Чикаго (скачать можно тут).
Теперь необходимо импортировать входные данные, создав на их основе набор RDD (Resilient Distributed Dataset). Это можно сделать с помощью функции textFile:
inspections = sc.textFile('Food_Inspections1.csv')\
.map(csvParse)
После создания RDD необходимо создать схему данных, определив типы данных для корректной работы алгоритма регрессии. Для создания схемы можно использовать класс StructType:
schema = StructType([
StructField("id", IntegerType(), False),
StructField("name", StringType(), False),
StructField("results", StringType(), False),
StructField("violations", StringType(), True)])
Созданная схема данных позволяет создать датафрейм и преобразовать его во временную таблицу, на основе которой будет выполняться прогностический анализ. Для создания датафрейма необходимо вызвать метод createDataframe() и передать в него созданную схему в качестве параметра, а затем с помощью метода registerTempTable() создать временную таблицу:
df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema)
df.registerTempTable('CountResults')
df.show(5)
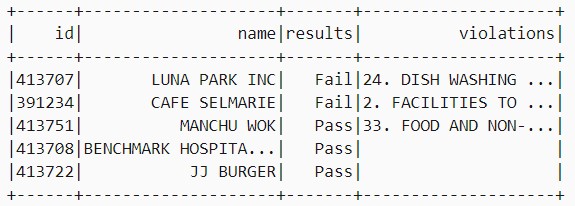
В качестве прогноза будут использоваться данные о результатах контроля качества еды (колонка «results»), поэтому для создания прогнозной модели необходимо создать новый датафрейм путем выборки данных о результатах. Для создания такого датафрейма необходимо представить старый датафрейм в виде пары «метка — результат», где метка 0 — это сбой (Fail), метка 1 — успех (Pass), а метка -1 представляет е неоднозначные результаты типа «Успех с условием (Pass with condition)». Следующий код на языке Python помогает разметить необходимые данные и создать на их основе новый датафрейм:
def labelForResults(s):
if s == 'Fail':
return 0.0
elif s == 'Pass w/ Conditions' or s == 'Pass':
return 1.0
else:
return -1.0
label = UserDefinedFunction(labelForResults, DoubleType())
labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')
После разметки данных необходимо преобразовать их в вектор признаков. Для этого необходимо пометить каждую строку результатов («results») с помощью маркеров для определения отдельных слов в каждой строке колонки. За это отвечает класс Tokenizer. Затем необходимо преобразовать каждый набор маркеров в вектор признаков с помощью класса HashingTF. Созданный вектор признаков необходимо передать в алгоритм логистической регрессии для создания модели с помощью класса LogisticRegression. Для того, чтобы корректно обучить ML-модель, необходимо все эти действия выполнять строго последовательно. За это отвечает класс Pipeline. Следующий код преобразовывает размеченные данные в вектор признаков и обучает прогнозную модель:
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Для оценки эффективности модели необходимо создать датафрейм с новыми тестовыми данными:
testData = sc.textFile('Food_Inspections2.csv')\
.map(csvParse) \
.map(lambda l: (int(l[0]), l[1], l[12], l[13]))
testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'")
После получения тестовых данных необходимо их классифицировать и на основе этого сделать прогноз. За классификацию и прогнозирование отвечает метод transform():
predictionsDf = model.transform(testDf)
predictionsDf.registerTempTable('Predictions')
Для оценки результатов прогноза можно создать итоговую визуализацию данных. Следующий код отвечает за визуализацию выходных данных [2]:
%%sql -q -o true_positive
SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'
%%sql -q -o false_positive
SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')
%%sql -q -o true_negative
SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'
%%sql -q -o false_negative
SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')
%%local
%matplotlib inline
import matplotlib.pyplot as plt
labels = ['True positive', 'False positive', 'True negative', 'False negative']
sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']]
colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral']
plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors)
plt.axis('equal')
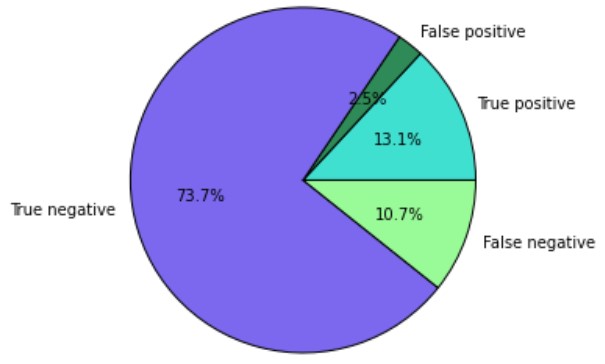
Таким образом, параллельность алгоритма логистической регрессии в Apache Spark позволяет обрабатывать огромные наборы данных и получать наиболее точные результаты классификации. Все это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы поговорим про создание аккумуляторов в Spark.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники

