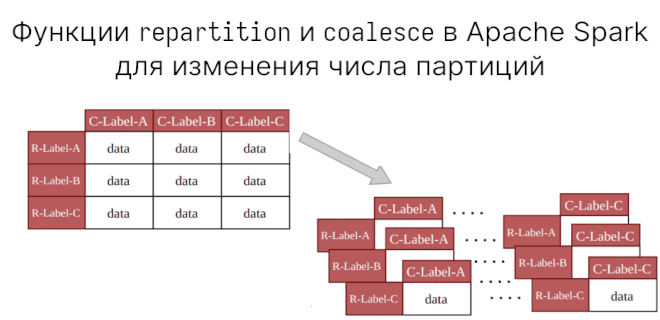
Мы уже говорили о создании партиций (partitions) на диске с помощью partitionBy. В Apache Spark есть еще функции для работы с партициями. Сегодня рассмотрим разницу межу repartition и coalesce в Apache Spark. repartition используется для увеличения или уменьшения партиций, а coalesce — только для уменьшения числа партиций наиболее эффективным образом.
Создание DataFrame с партициями
При создании приложения Spark мы можем указать, сколько исполнителей использовать, передав этот параметр в master:
spark = SparkSession.builder.master("local[*]").getOrCreate()
Здесь мы потребовали максимальное число исполнителей через *.
А теперь создадим DataFrame, который будет просто содержать 20 записей с числами:
df=spark.range(0,20)
Узнать, сколько партиций можно, вызвав через RDD метод getNumPartitions. Код на Python:
df.rdd.getNumPartitions() """ 2 """
На моей машине доступно два исполнителя (обычные ядра CPU).
К тому же можно узнать, как именно произошло разбиение на партиции, записав DataFrame на диск:
df.write.mode("overwrite").csv("partitions")
В директории partitions оказываются два файла формата CSV, которые и содержат партиции:
[roman]$ ls partitions part-00000-08b53e61-860b-4134-a6dc-8c7ca0fd58b3-c000.csv _SUCCESS part-00001-08b53e61-860b-4134-a6dc-8c7ca0fd58b3-c000.csv [roman]$ cat partitions/part-00000-08b53e61-860b-4134-a6dc-8c7ca0fd58b3-c000.csv 0 1 2 3 4 5 6 7 8 9 [roman]$ cat partitions/part-00001-08b53e61-860b-4134-a6dc-8c7ca0fd58b3-c000.csv 10 11 12 13 14 15 16 17 18 19
Всё это говорит нам о том, что в Spark партиции создаются при доступных исполнителях в оперативной памяти. Причем используется горизонтальное партицирование, т.е. когда исходный DataFrame делится на равные части. Однако не стоит наедятся, что партиции обязательно будут созданы при любом датасете. Это решение остается на усмотрение Spark. Поэтому есть функции, которые увеличивают или уменьшают количество партиций.
Что делает repartition?
Функция (или метод) repartition используется для увеличения или уменьшения количества партиций. Например, прочитаем датасет iris. По умолчанию будет создана одна партиция, но мы увеличим это количества на 2:
df = spark.read.csv("iris.csv", header=True)
print(df.rdd.getNumPartitions()) # 1
df = df.repartition(2)
print(df.rdd.getNumPartitions()) # 2
Таким образом, функция repartition поделили исходный датасет на две партиции. Мы можем в этом убедиться, снова записав DataFrame на диск:
df.write.mode("overwrite").csv("partitions")
Заглянем снова в эту директорию:
[roman]$ ls partitions/ part-00000-1874f2b1-73ee-4346-8210-1cd31941fba9-c000.csv _SUCCESS part-00001-1874f2b1-73ee-4346-8210-1cd31941fba9-c000.csv [roman]$ head partitions/part-00000-1874f2b1-73ee-4346-8210-1cd31941fba9-c000.csv 6.7,3.0,5.2,2.3,virginica 6.4,2.8,5.6,2.1,virginica 6.3,2.7,4.9,1.8,virginica 6.2,2.8,4.8,1.8,virginica 6.0,2.2,4.0,1.0,versicolor 6.4,2.8,5.6,2.2,virginica 5.8,2.7,5.1,1.9,virginica 5.5,3.5,1.3,0.2,setosa 6.1,2.8,4.0,1.3,versicolor 5.3,3.7,1.5,0.2,setosa [roman]$ wc -l partitions/part-00000-1874f2b1-73ee-4346-8210-1cd31941fba9-c000.csv 75 [roman]$ head partitions/part-00001-1874f2b1-73ee-4346-8210-1cd31941fba9-c000.csv 6.3,2.3,4.4,1.3,versicolor 6.6,3.0,4.4,1.4,versicolor 5.0,3.4,1.5,0.2,setosa 7.3,2.9,6.3,1.8,virginica 6.3,3.3,6.0,2.5,virginica 5.8,2.7,5.1,1.9,virginica 4.6,3.2,1.4,0.2,setosa 6.1,2.6,5.6,1.4,virginica 5.9,3.2,4.8,1.8,versicolor 7.7,3.0,6.1,2.3,virginica [roman]$ wc -l partitions/part-00001-1874f2b1-73ee-4346-8210-1cd31941fba9-c000.csv 75
Исходный датасет содержал 150 записей, каждая из партиций содержит ровно половину. В отличие от partitionBy, который делит данные на основании уникальных значений столбца(ов), функция repartition просто делит на равные части, причем делает это с полной перетасовкой (shuffle).
Что делает функция coalesce в Apache Spark
С другой стороны, coalesce предназначена только для уменьшения числа партиций. Иными словам, она объединяет партиции и при этом минимизирует количество перетасовок. Так как перетасовки в этом случае нет, то можно надеяться на то, что уменьшение партиций будет быстрее, чем при использовании repartition.
Функция принимает уменьшенное число партиций. Если это число больше, чем текущее, то ничего не произойдет. Например, уменьшим партиции нашего датасета:
df = df.coalesce(1) df.rdd.getNumPartitions() # 1
Если мы сильно уменьшаем число партиций (как в этом примере до 1), то вычисления, скорее всего, произойдут на меньшем числе узлов. Чтобы этого избежать, можно использовать repartition, который выполнит перетасовку, а значит для этого этапа вычисления будут выполнены в распределенном режиме.
Где используется repartition или coalesce
Ниже перечислены практики применения по изменению числа партиций в Apache Spark.
- Запись в файл (по умолчанию будут записаны именно партиции, поэтому чтобы получить сразу один файл, можно выполнить
coalesce(1)) - Уменьшать партиции после запуска фильтров. Число партиций после фильтрации не уменьшается, в итоге может возникнуть проблема, когда этих партиций слишком много.
- После использования функции
partitionBy, которая записывает партиции на диск. Чтобы получить партиции в оперативной памяти, необходимо вызватьrepartitionилиcoalesce
Код курса
GRAS
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Больше подробностей о работе с партициями в Apache Spark вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков

