Оконные функции (window functions) в Apache Spark работают на группах строк (это может быть фрейм, партиция, бакет) и возвращает одно значение, полученное в результате вычисления. Группа строк называется окном (window), отсюда и название функций. Spark SQL поддерживает три вида оконных функций:
- ранжирующие (ranking):
dense_rank,ntil,percent_rank,rank,row_number; - аналитические (analytic):
cume_dist,lag,lead,nth_value(появился в Spark 3.1); - агрегирующие (aggregate):
min,max,count,sum,stdи т.д.
Оконные функции очень полезны для вычисления статистических значений или получения строк относительно некоторой заданной.
Оконные функции в классическом SQL
В классическом SQL оконная функция определяется следующим образом:
function OVER([PARTITION BY col1] [ORDER BY col2] [RANGE|ROWS])
Итак, function является сама оконная функция. PARTITION BY мы указываем нужно ли производить группировку, что аналогично GROUP BY, если партицирование не указано, то рассматриваться будет вся таблица. Также можно сортировать полученные записи через ORDER BY. А также выбрать границы окна.
Окном является группа строк, над которой происходит вычисление функции. Размер окна отсчитывается от текущей строки. По умолчанию границы определяется так:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
Что говорит нам о том, что окно отсчитывается от текущей строки до самой первой строки партиции. Таким образом, можно построить нарастающий итог.
Также можно указать окном всю партицию:
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
Можете считать UNBOUNDED очень большим числом. Поэтому вместо него можно подставлять свои числа. Так можно считать окном две строки перед и две строк после относительно текущей:
RANGE BETWEEN 2 PRECEDING AND 2 FOLLOWING
Помимо границ фрейма RANGE существует ROWS. Отличаются они тем, как рассматривают дубликаты в столбце, преданному ORDER BY. При использовании ROWS записи с одинаковым значением в ORDER BY рассматриваются как отдельные строки. При использовании RANGE — как одна строка (см. рис ниже).
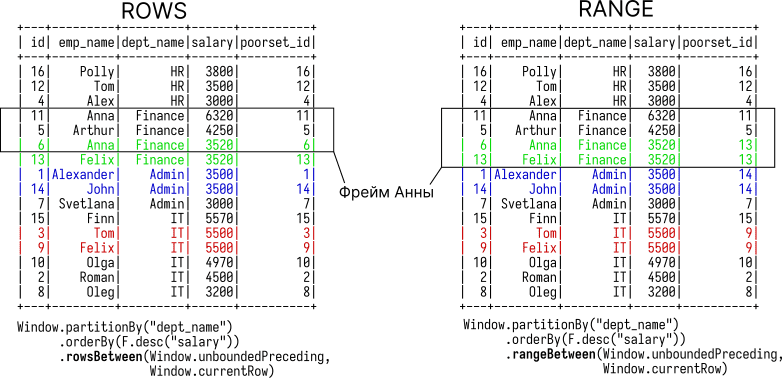
Класс Window
Чтобы применить оконные функции, нужно инициализировать экземпляр WindowSpec. Делается это через методы класса Window:
orderBy(*cols)partitionBy(*cols)rangeBetween(start, end)rowsBetween(start, end)
Экземпляр этого класса передается методу over из оконных функций. Например, вот так можно взять последнее значение из окна, которое определяется всей партицией:
import pyspark.sql.functions as F
from pyspark.sql import Window
w = Window.partitionBy("dept_name") \
.orderBy(F.desc("salary")) \
.rangeBetween(Window.unboundedPreceding,
Window.unboundedFollowing)
df.withColumn("poorset_id", F.last("id").over(w)).show()
Для текущего строки используется Window.currentRow. Если хотите вместо unboundedPreceding использовать свои границы, то нужно использовать отрицательное число; например, окно из двух строк перед и двух строк после относительно текущей:
w = Window.partitionBy("dept_name") \
.orderBy(F.desc("salary")) \
.rowsBetween(-2, 2)
Ниже статьи с конкретными примерами использования оконных функций: