В предыдущей статье мы говорили о ранжирующих функциях из семейство оконных (window function) в PySpark. В этой статье пойдет речь об аналитических функциях LEAD и LAG, которые помогают сдвигать строки.
Данные с затонувшего Титаника
Возьмем для примера датасет с затонувшим Титаником. Его можно взять тут. У него много столбцов, поэтому вы покажем только его схему.
df = spark.read.csv("titanic_dataset.csv", header=True, inferScheme=True)
"""
root
|-- PassengerId: integer (nullable = true)
|-- Survived: integer (nullable = true)
|-- Pclass: integer (nullable = true)
|-- Name: string (nullable = true)
|-- Sex: string (nullable = true)
|-- Age: double (nullable = true)
|-- SibSp: integer (nullable = true)
|-- Parch: integer (nullable = true)
|-- Ticket: string (nullable = true)
|-- Fare: double (nullable = true)
|-- Cabin: string (nullable = true)
|-- Embarked: string (nullable = true)
"""
Что делает функция LAG в Apache PySpark
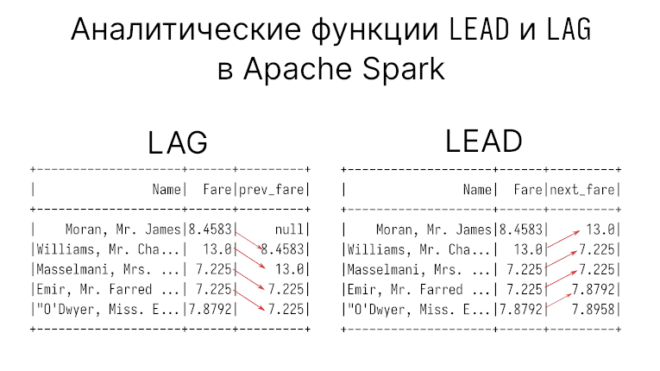
Функция LAG берет значения заданного столбца из предыдущих строк. Можно также указать смещение, от которого нужно начать считать. Такая функция позволяет сравнивать значения одного и того же столбца: например, если есть столбец со временными замерами, тогда мы можем узнать сколько, было затрачено времени между замерами.
Для примера возьмем предыдущие значения оплаты за проезд Fare, SQL-запрос для его получения выглядит следующим образом:
SELECT t.Name, t.Fare,
LAG(t.Fare) OVER(ORDER BY t.Age) as prev_fare
FROM titanic t;
Этот же запрос в PySpark:
import pyspark.sql.functions as F
from pyspark.sql import Window
w = Window.orderBy("Age")
df.select(
"Name", "Fare",
F.lag("Fare").over(w).alias("prev_fare")
)
"""
+--------------------+------+---------+
| Name| Fare|prev_fare|
+--------------------+------+---------+
| Moran, Mr. James|8.4583| null|
|Williams, Mr. Cha...| 13.0| 8.4583|
|Masselmani, Mrs. ...| 7.225| 13.0|
|Emir, Mr. Farred ...| 7.225| 7.225|
|"O'Dwyer, Miss. E...|7.8792| 7.225|
+--------------------+------+---------+
"""
Как можно заметить, самое первое значение полученного столбца является null. Действительно, у первой строки нет предыдущего значения, поэтому ему по умолчанию выдается null. Вместо null можно выдавать свое значение, которое передается третьим параметром функции LAG.
Указываем группы с помощью PARTITION BY
Мы можем также указать партицию (группу), по которой нужно выполнять оконную функцию. например, вычислим предыдущие значения для каждого класса пассажира Pclass. Кроме того, давайте упорядочим результат в порядке убывания возраста пассажиры, т.е. самые старшие впереди.
SQL-запрос выглядит так:
SELECT t.Name, t.Age, t.Pclass, t.Fare,
LAG(t.Fare)
OVER(PARTITION BY t.Pclass ORDER BY t.Age) as prev_fare
FROM titanic t;
В PySpark API вот так:
w = Window.partitionBy("Pclass").orderBy(F.desc("Age"))
df.select(
"Name", "Age", "Pclass", "Fare",
F.lag("Fare").over(w).alias("prev_fare")
)
"""
+--------------------+----+------+-------+---------+
| Name| Age|Pclass| Fare|prev_fare|
+--------------------+----+------+-------+---------+
|Barkworth, Mr. Al...|80.0| 1| 30.0| null|
|Goldschmidt, Mr. ...|71.0| 1|34.6542| 30.0|
|Artagaveytia, Mr....|71.0| 1|49.5042| 34.6542|
|Crosby, Capt. Edw...|70.0| 1| 71.0| 49.5042|
|Ostby, Mr. Engelh...|65.0| 1|61.9792| 71.0|
|Millet, Mr. Franc...|65.0| 1| 26.55| 61.9792|
| Fortune, Mr. Mark|64.0| 1| 263.0| 26.55|
|Nicholson, Mr. Ar...|64.0| 1| 26.0| 263.0|
+--------------------+----+------+-------+---------+
"""
Чтобы удостовериться, что посчиталось предыдущие значения по каждому классу, используем тот трюк с ROW NUMBER, который мы демонстрировали в одной из прошлой статьи.
df.select(
"Name", "Age", "Pclass", "Fare",
F.lag("Fare").over(w).alias("prev_fare"),
F.row_number().over(w).alias("rn")
).where("rn < 4")
"""
+--------------------+----+------+-------+---------+---+
| Name| Age|Pclass| Fare|prev_fare| rn|
+--------------------+----+------+-------+---------+---+
|Barkworth, Mr. Al...|80.0| 1| 30.0| null| 1|
|Goldschmidt, Mr. ...|71.0| 1|34.6542| 30.0| 2|
|Artagaveytia, Mr....|71.0| 1|49.5042| 34.6542| 3|
| Svensson, Mr. Johan|74.0| 3| 7.775| null| 1|
|Connors, Mr. Patrick|70.5| 3| 7.75| 7.775| 2|
| Duane, Mr. Frank|65.0| 3| 7.75| 7.75| 3|
|Mitchell, Mr. Hen...|70.0| 2| 10.5| null| 1|
|Wheadon, Mr. Edwa...|66.0| 2| 10.5| 10.5| 2|
| Harris, Mr. George|62.0| 2| 10.5| 10.5| 3|
+--------------------+----+------+-------+---------+---+
"""
Каждая группа с предыдущими значениями столбца Fare начинается с null. Значит запрос правильный.
Определяем свое смещение и значение по умолчанию
Во всех предыдущих случаях столбец смещался только на одну строку. Также первому значению строки выдавалось null. Это поведение можно изменить, передав свое смещение и свое заполняемое значение через параметры функции.
Например, выберем смещение, равное 2, а первые две строки заполним нулями:
df.select(
"Name", "Age", "Pclass", "Fare",
F.lag("Fare", 2, 0).over(w).alias("prev_fare"),
F.row_number().over(w).alias("rn")
).where("rn < 4").show(9)
"""
+--------------------+----+------+-------+---------+---+
| Name| Age|Pclass| Fare|prev_fare| rn|
+--------------------+----+------+-------+---------+---+
|Barkworth, Mr. Al...|80.0| 1| 30.0| 0.0| 1|
|Goldschmidt, Mr. ...|71.0| 1|34.6542| 0.0| 2|
|Artagaveytia, Mr....|71.0| 1|49.5042| 30.0| 3|
| Svensson, Mr. Johan|74.0| 3| 7.775| 0.0| 1|
|Connors, Mr. Patrick|70.5| 3| 7.75| 0.0| 2|
| Duane, Mr. Frank|65.0| 3| 7.75| 7.775| 3|
|Mitchell, Mr. Hen...|70.0| 2| 10.5| 0.0| 1|
|Wheadon, Mr. Edwa...|66.0| 2| 10.5| 0.0| 2|
| Harris, Mr. George|62.0| 2| 10.5| 10.5| 3|
+--------------------+----+------+-------+---------+---+
"""
Функция LEAD выбирает следующие строки в PySpark
Функция LEAD — противоположная LEAD, т.е. отбирает следующие строки заданного столбца. Следовательно, незаполненными будут строки не первые, а последние. Функция также может принимать смещение и значение по умолчанию для незаполненных строк.
Продемонстрируем работу функции LEAD и сравним ее с LAG:
w = Window.orderBy("Age")
df.select(
"Name", "Fare",
F.lag("Fare").over(w).alias("prev_fare"),
F.lead("Fare").over(w).alias("next_fare")
)
"""
+--------------------+------+---------+---------+
| Name| Fare|prev_fare|next_fare|
+--------------------+------+---------+---------+
| Moran, Mr. James|8.4583| null| 13.0|
|Williams, Mr. Cha...| 13.0| 8.4583| 7.225|
|Masselmani, Mrs. ...| 7.225| 13.0| 7.225|
|Emir, Mr. Farred ...| 7.225| 7.225| 7.8792|
|"O'Dwyer, Miss. E...|7.8792| 7.225| 7.8958|
+--------------------+------+---------+---------+
"""
Как видим, первые строки заполнены, потому что у первой строки есть следующее значение.
Убедимся, что последнее значение результат функции LEAD является null с помощью функции tail, которая возвращает список из последних строк:
df.select(
"Name", "Fare",
F.lead("Fare").over(w).alias("next_fare")
).tail(3)
"""
[Row(Name='Artagaveytia, Mr. Ramon', Fare=49.5042, next_fare=7.775, last_val=49.5042),
Row(Name='Svensson, Mr. Johan', Fare=7.775, next_fare=30.0, last_val=7.775),
Row(Name='Barkworth, Mr. Algernon Henry Wilson', Fare=30.0, next_fare=None, last_val=30.0)]
"""
Код курса
SPOT
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Еще больше подробностей об оконных функциях в PySpark вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и IT-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков

