В прошлой статье мы говорили о датах в Apache Spark. Сегодня затронем представление дата/время или timestamp. В этой статье вы узнаете как представить и преобразовать строку в виде даты/времени, как перевести дату/время в секунды и обратно, а также как работать с часами поясами в PySpark.
Представление даты/времени в PySpark
Простой способ представления timestamp является обычная строка, заданная в формате yyyy-MM-dd HH:mm:ss.S, где S — это доли секунды. Если порядок должен быть соблюден, то справа налево время порядки можно опускать. Это значит, что мы можем не добавлять секунды, минуты, часы и день, тогда эти значения будут приведены в начальное значение (например, час до 0). При это если нельзя таким образом опустить час и оставить секунды и т.д.
Итак, DataFrame создается следующим образом:
df = spark.createDataFrame([
('Anton', '1985-03-12 01:32:00'),
('Valen', '2003-07-25 23:16:59'),
('Andry', '1993-03-12 17:45:00'),
('Alexy', '1979-12-01 19:05:17')],
['name', 'birth']
)
Доли секунды мы опустили. Тип столбца при этом будет строкой. Если вы хотите задать определенный тип, то можно сделать вот так:
from pyspark.sql.types import (StructType, StructField,
StringType, TimestampType)
from datetime import datetime
parse_tm = lambda x: datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
schema = StructType([
StructField('name', StringType()),
StructField('birth', TimestampType())
])
data = [
('Anton', parse_tm('1985-03-12 01:32:00')),
('Valen', parse_tm('2003-07-25 23:16:59')),
('Andry', parse_tm('1993-03-12 17:45:00')),
('Alexy', parse_tm('1979-12-01 19:05:17'))
]
df = spark.createDataFrame(data, schema)
df.printSchema()
"""
root
|-- name: string (nullable = true)
|-- birth: timestamp (nullable = true)
"""
Здесь мы создали лямбда-функцию, которая парсит строковое значение. Можно было просто передавать значения параметры объекта datetime друг за другом, но так будет менее наглядно.
Потоковая обработка в Apache Spark
Код курса
SPOT
Ближайшая дата курса
25 августа, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Правильное представление даты/времени
Часто приходится читать датасеты, а не создавать их явным образом. Чтение файла с датой/временем может не иметь заданной структуры (например, используются точки вместо дефиса), тогда стоит воспользоваться функцией to_timestamp.
Например, мы прочитали датасет, и он следующий:
df = spark.createDataFrame([
('Anton', '1985.03.12T01:32:00'),
('Valen', '2003.07.25T23:16:59'),
('Andry', '1993.03.12T17:45:00'),
('Alexy', '1979.12.01T19:05:17')],
['name', 'birth']
)
Здесь используются точки, дата разделены временем символом T. Тогда для преобразования строки в дату/время в PySpark нужно выполнить следующий код:
fmt = "yyyy.MM.dd'T'HH:mm:ss"
df.withColumn("res", F.to_timestamp("birth", fmt))
"""
+-----+-------------------+-------------------+
| name| birth| res|
+-----+-------------------+-------------------+
|Anton|1985.03.12T01:32:00|1985-03-12 01:32:00|
|Valen|2003.07.25T23:16:59|2003-07-25 23:16:59|
|Andry|1993.03.12T17:45:00|1993-03-12 17:45:00|
|Alexy|1979.12.01T19:05:17|1979-12-01 19:05:17|
+-----+-------------------+-------------------+
"""
Обратите внимание, что для игнорирования ненужных символов используется одиночный апостроф '. Из-за этого пришлось даже отказаться от прошлого стиля кодирования, когда строки заключали в этот апостроф. Если вы не хотите отступаться от своих принципов, можете использовать символ экранирования \:
fmt = 'yyyy.MM.dd\'T\'HH:mm:ss'
Также стоит заметить, что формат представления отличается от применяемых в Unix-ах. Можете посмотреть выше на лямбда-функцию, там использовалась совсем другая нотация через %. Формат представления даты/времени в Apache Spark вы можете посмотреть в документации.
Получение часов, минут, секунд
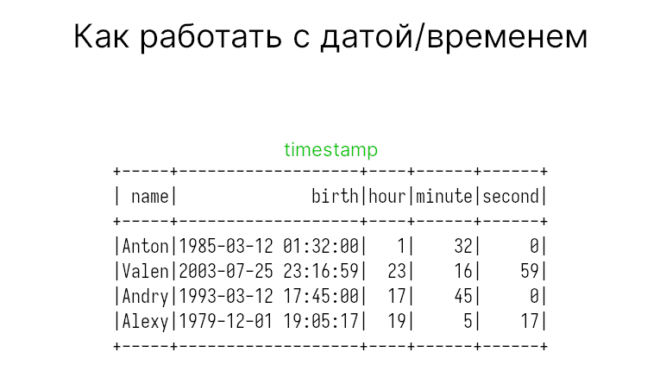
Помимо года, месяца и дня можно получать час, минуту и секунду (доли секунд нет). В этом случае используются функции hour, minute и second.
df.withColumn('hour', F.hour('birth')) \
.withColumn('minute', F.minute('birth')) \
.withColumn('second', F.second('birth')) \
"""
+-----+-------------------+----+------+------+
| name| birth|hour|minute|second|
+-----+-------------------+----+------+------+
|Anton|1985-03-12 01:32:00| 1| 32| 0|
|Valen|2003-07-25 23:16:59| 23| 16| 59|
|Andry|1993-03-12 17:45:00| 17| 45| 0|
|Alexy|1979-12-01 19:05:17| 19| 5| 17|
+-----+-------------------+----+------+------+
"""
Unix-овые функции в PySpark
В PySpark также есть функции для работы со временем: unix_timestamp и from_unixtime. Первая функция похожа на to_timestamp, но только переводит в не объект datetime, а в секунды с начала эпохи (1 января 1970). Вторая функция конвертирует секунды в строковое значение. В PySpark 3.1.0 появилась функция timestamp_seconds, которая приводит секунды не в строку, а сразу в timestamp.
С секундами проще работать, поскольку они представлены обычным числом, а не каким-то объектом. Так что можете спокойно их использовать для расчетов.
Конвертация в другой часовой пояс
Если вы хотите перевести дату/время в другой часовой пояс, то используйте функцию from_utc_timestamp. Тогда ваша даты будут считаться UTC+0.
Вторым параметром функция принимает часовую зону, форматы здесь следующие:
- Идентификатор в форме
регион/город, например,Europe/Moscow; - Часовой сдвиг относительно UTC+0 в форме
(+|-)HH:mm, например,+7:00(можно добавитьUTC—UTC+7:00).
Список часовых зон стран можете взять из Википедии.
df.withColumn('res1', F.from_utc_timestamp('birth', 'America/Los_Angeles')) \
.withColumn('res2', F.from_utc_timestamp('birth', 'UTC-6:30'))
"""
+-----+-------------------+-------------------+-------------------+
| name| birth| res1| res2|
+-----+-------------------+-------------------+-------------------+
|Anton|1985-03-12 01:32:00|1985-03-11 17:32:00|1985-03-11 19:02:00|
|Valen|2003-07-25 23:16:59|2003-07-25 16:16:59|2003-07-25 16:46:59|
|Andry|1993-03-12 17:45:00|1993-03-12 09:45:00|1993-03-12 11:15:00|
|Alexy|1979-12-01 19:05:17|1979-12-01 11:05:17|1979-12-01 12:35:17|
+-----+-------------------+-------------------+-------------------+
"""
Еще больше о работе с датами и врменем в Apache Spark вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:

