Сегодня расскажем о способах работы с датами в Apache Spark. В этой статье вы узнаете: как создать DataFrame с датами; как преобразовать столбец в корректное отображение даты или изменить его формат; как получить год, месяц, день и квартал; как вычитать и складывать даты в Apache PySpark.
Инициализация DataFrame с датами
Самым простым способом создания таблицы с датами является представление записей этой самой даты в виде строки YYYY-MM-DD. В данном случае порядок: год, месяц, день — важен, иначе функции для работы с датами не будут работать.
DataFrame с датами может выглядеть так:
df = spark.createDataFrame([
('Anton', '1985-03-12'),
('Valen', '2003-07-25'),
('Andry', '1993-03-12'),
('Alexy', '1979-12-01')],
['name', 'birth']
)
В PySpark тип столбца с датами будет идентифицироваться как строка, но тем не менее рассматриваемые функции можно спокойно применять.
Можно быть более педантичным и указать типы столбцов явно через DateType. В этом случае нужно использовать объект date из модуля datetime. В этот объект нужно передать год, месяц и день в виде чисел.
Так, таблицы через DateType создает следующим образом:
from pyspark.sql.types import StructType, StructField, StringType, DateType
from datetime import date
schema = StructType([
StructField('name', StringType()),
StructField('birth', DateType())
])
data = [
('Anton', date(1985, 3, 12)),
('Valen', date(2003, 7, 25)),
('Andry', date(1993, 3, 12)),
('Alexy', date(1979, 12, 29))
]
df = spark.createDataFrame(data, schema)
В большинстве случаев таблицы не создаются вот так явно, а читаются из файлов. При чтении файла в DataFrame также можно указать дополнительным параметром dateFormat и надеяться, что даты будут правильно интерпретированы. Однако в PySpark, в отличие от Pandas, нет возможности указать, какой именно столбец содержит даты, поэтому такой трюк, скорее всего, не пройдет. Тем не менее, вы также можете преобразовать строки в даты функцией to_date, если они не имеют правильного порядка.
Как преобразовать строки в корректные даты в Spark
Допустим, в исходной таблице порядок представления дат не тот. В этом случае можно воспользоваться SQL-функцией to_date. Формат представления, который передается вторым параметром, должен быть ровно таким, каким представлен в документации. Unix’овые форматы с % не сработают.
Машинное обучение в Apache Spark
Код курса
MLSP
Ближайшая дата курса
по запросу
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Итак, имеется таблица, в которой сначала идет месяц, год, день, затем какие-то непонятные символы RST:
df = spark.createDataFrame([
('Anton', '03/1985/12 RST'),
('Valen', '07/2003/25 RST'),
('Andry', '03/1993/12 RST'),
('Alexy', '12/1979/01 RST')],
['name', 'birth']
)
Чтобы преобразовать данный столбец в корректное представление даты, нужно вызвать функцию to_date:
df.withColumn('birth', F.to_date("birth", "MM/yyyy/dd 'RST"))
"""
+-----+----------+
| name| birth|
+-----+----------+
|Anton|1985-03-12|
|Valen|2003-07-25|
|Andry|1993-03-12|
|Alexy|1979-12-01|
+-----+----------+
"""
Здесь одиночный апостроф ' обозначает, что после него идут символы, которые не нужно интерпретировать.
Извлечение года, месяца или дня в Apache Spark
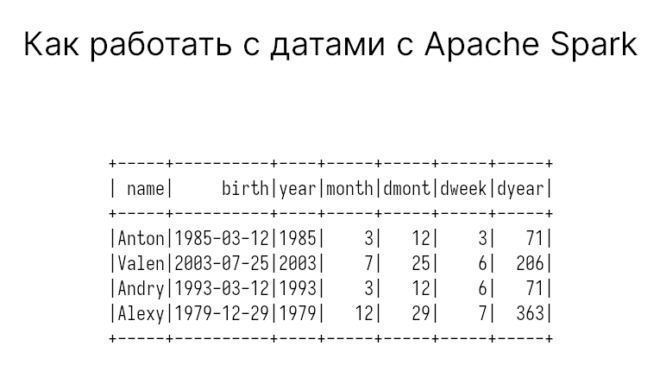
Возможно вам понадобятся конкретный год, месяц или день из столбца с датами. Тогда воспользуйтесь функциями year, month, dayofmonth (день месяца), dayofweek (день недели), dayofyear (день из всего года).
df.withColumn('year', F.year('birth')) \
.withColumn('month', F.month('birth')) \
.withColumn('dmont', F.dayofmonth('birth')) \
.withColumn('dweek', F.dayofweek('birth')) \
.withColumn('dyear', F.dayofyear('birth')) \
.show()
"""
+-----+----------+----+-----+-----+-----+-----+
| name| birth|year|month|dmont|dweek|dyear|
+-----+----------+----+-----+-----+-----+-----+
|Anton|1985-03-12|1985| 3| 12| 3| 71|
|Valen|2003-07-25|2003| 7| 25| 6| 206|
|Andry|1993-03-12|1993| 3| 12| 6| 71|
|Alexy|1979-12-29|1979| 12| 29| 7| 363|
+-----+----------+----+-----+-----+-----+-----+
"""
Также есть дополнительные функции без параметров:
quarterвозвращает квартал года (1, 2, 3 или 4);weekofyearвозвращает номер недели в году (от 1 до 52);last_dayвозвращает последний день месяца (от 28 до 31);
Прибавляем, отнимаем даты
Чтобы прибавить заданное количество месяцев или дней, используются функции add_months или date_add. Вторым параметром передается количество месяцев или дней, которые нужно прибавить.
df.withColumn('add_month', F.add_months('birth', 12)) \
.withColumn('add_days', F.date_add('birth', 31))
"""
+-----+----------+----------+----------+
| name| birth| add_month| add_days|
+-----+----------+----------+----------+
|Anton|1985-03-12|1986-03-12|1985-04-12|
|Valen|2003-07-25|2004-07-25|2003-08-25|
|Andry|1993-03-12|1994-03-12|1993-04-12|
|Alexy|1979-12-01|1980-12-01|1980-01-01|
+-----+----------+----------+----------+
"""
Функции для прибавление года нет, поэтому можно использовать add_months со значением кратным 12.
Чтобы отнять дату, используются функции date_sub или datediff. Первая функция отнимает заданное количество дней. Вторая отнимает выполняет вычитание дат, в т.ч. двух столбцов. Обе функции возвращают количество дней.
Допустим, требуется узнать сколько лет человеку, отсчитывая от сегодняшнего дня. Тогда мы можем воспользоваться еще функцией current_date для получения текущего времени:
n_days = 365
years = F.datediff(F.current_date(), 'birth') / n_days
df.withColumn('years', years.cast('int'))
"""
+-----+----------+-----+
| name| birth|years|
+-----+----------+-----+
|Anton|1985-03-12| 36|
|Valen|2003-07-25| 18|
|Andry|1993-03-12| 28|
|Alexy|1979-12-01| 42|
+-----+----------+-----+
"""
Мы использовали явное преобразование в int, иначе результатом было бы число с плавающей точкой, а округление до целого привело бы к неправильному году.
Есть еще функция months_between, но она возвращает разницу в месяцах. Эта функция также имеет третий параметр roundOff, по умолчанию равный True, который округляет до 8 знаков после запятой, если не передано значение False.
Еще различные функции для работы с датами в Apache Spark
Если вам понадобилось преобразовать даты в какой-то другой формат, то используйте функцию date_format. Например, требуется ограничить порядки точкой, а не дефисом:
df.withColumn('res', F.date_format('birth', 'dd.MM.yyyy'))
"""
+-----+----------+----------+
| name| birth| res|
+-----+----------+----------+
|Anton|1985-03-12|12.03.1985|
|Valen|2003-07-25|25.07.2003|
|Andry|1993-03-12|12.03.1993|
|Alexy|1979-12-01|01.12.1979|
+-----+----------+----------+
"""
Функция date_trunc возвращает даты, округленные до заданного формата. Она может понадобится, когда нужно округлить дату до начало года, месяца, недели или квартала. Эта функция немного странная в том, что она принимает имя столбца вторым параметром и возвращает объект timestamp (время также будет включено).
Например, получим даты с начала квартала:
df.withColumn('res', F.date_trunc('quarter', 'birth'))
"""
+-----+----------+-------------------+
| name| birth| res|
+-----+----------+-------------------+
|Anton|1985-03-12|1985-01-01 00:00:00|
|Valen|2003-07-25|2003-07-01 00:00:00|
|Andry|1993-03-12|1993-01-01 00:00:00|
|Alexy|1979-12-01|1979-10-01 00:00:00|
+-----+----------+-------------------+
"""
А вот функция trunc, наоборот, принимает первым параметром сам столбец и возвращает объект DateType. А делает все то же самое:
df.withColumn('res', F.trunc('birth', 'month')).show()
"""
+-----+----------+----------+
| name| birth| res|
+-----+----------+----------+
|Anton|1985-03-12|1985-03-01|
|Valen|2003-07-25|2003-07-01|
|Andry|1993-03-12|1993-03-01|
|Alexy|1979-12-01|1979-12-01|
+-----+----------+----------+
"""
Напоследок упомянем функцию next_day, которая возвращает ближайшую следующую дату заданного дня недели. Например, next_day('2022-01-30', 'Fri') вернет значение 2022-02-04, поскольку ближайшая следующая пятница именно этого числа.
Еще больше подробностей о преобразовании и анализе данных вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:

