В этой статье поговорим про модуль Spark Streaming, который входит в популярный Big Data фреймворк Apache Spark. Читайте далее про ключевые характеристики этого компонента, его архитектуру и особенности практического использования на реальном примере из области Data Science.
Как работает Spark Streaming: особенности архитектуры
Напомним, Spark Streaming позволяет вести обработку данных в режиме реального времени. При этом обработка данных ведется не целиком, а частями, когда отдельные потоки информации разбиваются на микро-пакеты (micro-batch). Это обусловлено особенностями архитектуры Spark Streaming, которую мы рассмотрим далее.
Микропакетная архитектура и механизм контрольных точек
Спарк Streaming построен с применением микро-пакетной архитектуры, когда главный поток данных состоит из последовательности небольших пакетов данных. При этом новые пакеты создаются регулярно через заданный интервал времени. В начале каждого интервала времени создается новый пакет, который включает в себя любые данные, поступившие в течение этого интервала. В конце интервала пакет прекращает свое увеличение. Размер интервала определяется таким параметром, как интервал пакетирования (batch interval). Обычно этот интервал выбирается в промежутке от 500 миллисекунд до нескольких секунд. Каждый пакет формирует коллекцию RDD и обрабатывается заданием Spark, который создает в этот момент времени другой набор RDD. Результаты обработки пакета затем передаются внешним системам для анализа и дальнейшей обработки. В качестве программной абстракции Spark Streaming использует дискретизированный поток (DStream), который представляет собой последовательность наборов RDD, где каждый отдельный набор RDD соответствует одному отрезку времени. Такие потоки можно создавать из внешних источников данных или путем применения различных преобразований к другим потокам того же вида. Для каждого источника данных модуль Spark Streaming автоматически запускает приемники (receivers), которые служат для сбора данных из источников и сохранения их в наборы RDD. Spark Streaming поддерживает механизм копирования данных в контрольных точках (checkpointing), который способен сохранять состояние программы в файловой системе, например, HDFS в Apache Hadoop или Amazon S3. Такое копирование обычно выполняется через каждые 5-10 пакетов. Благодаря этому Spark Streaming обеспечивает возможность восстановления данных в случае сбоя – вычисления продолжатся от последней контрольной точки.
4 главных преимущества Спарк Streaming
С учетом вышеописанных особенностей архитектуры, перечислим основные достоинства Spark Streaming для разработчика Big Data приложений:
- копирование данных в контрольных точках ограничивает объем вычислений в случае отказа;
- отказоустойчивость рабочих узлов благодаря одновременному копированию на них данных из внешних источников;
- отказоустойчивость приемников данных – в случае отказа одного из приемников Spark Streaming запустит приемники на других узлах кластера;
- строго однократная семантика доставки сообщений (exactly-once) – если рабочий узел выходит из строя в момент обработки, окончательный результат преобразования не изменится.
Начало работы со Спарк Streaming: несколько практических примеров
Для того, чтобы начать работу с модулем Spark Streaming, необходимо настроить базовую конфигурацию. Точкой входа служит класс StreamingContext, поэтому его необходимо импортировать для доступа к функциям Spark Streaming:
from pyspark.streaming import StreamingContext
Теперь необходимо создать объект StreamingContext:
ssc = StreamingContext(sc, 1)
Далее мы можем создать набор RDD для дискретизированного потока с помощью метода sparkContext.parallelize():
queue_rdd += [ssc.sparkContext.parallelize([i, i+1])]
А теперь давайте создадим очередь пакетов, которая будет обрабатываться в одном потоке с помощью метода queueStream():
queue_rdd += [ssc.sparkContext.parallelize([i, i+1])]
Мы разбили наш RDD на отдельные пакеты в очереди потока DStream. Теперь можно работать с ней в пределах всего потока. Следующий код языке Python показывает пример организации очереди пакетов RDD с числовыми данными, каждый из которых содержит по 2 элемента. В качестве иллюстрации вычислим суммы этих элементов до тех пор, пока не закончится очередь:
from operator import add, sub
from time import sleep
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
ssc = StreamingContext(sc, 1)
queue_rdd = []
for i in range(5):
queue_rdd += [ssc.sparkContext.parallelize([i, i+1])]
inputStream = ssc.queueStream(queue_rdd)
inputStream.map(lambda x: "Input data: " + str(x)).pprint()
inputStream.reduce(add)\
.map(lambda x: "Output data: " + str(x))\
.pprint()
ssc.start()
sleep(5)
ssc.stop(stopSparkContext=True, stopGraceFully=True)
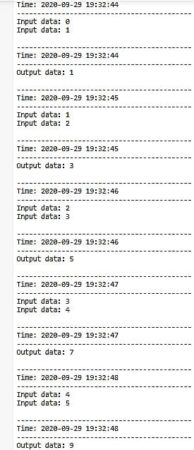
Как мы видим, очередь состоит из 5 пакетов, которые выполняются последовательно. Как только все пакеты в очереди закончились, и все 5 сумм были посчитаны, программа завершила свое выполнение.
Таким образом, отказоустойчивость и гарантия получения верного результата Spark Streaming делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы поговорим про другой важный компонент Apache Spark – Spark MLLib.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.

