
В этой статье поговорим про модуль Spark SQL, который входит в популярный стек Big Data фреймворка Apache Spark. Также рассмотрим основные особенности этого компонента, его архитектуру и особенности практического использования на реальных примерах.
Как работает Spark SQL: архитектура и принципы
Компонент Spark SQL позволяет вести работу со структурированными большими данными (Big Data) и может выступать в качестве механизма для распределенного SQL-запроса. Архитектура этого компонента включает в себя следующие составляющие:
- коллекция данных (dataframe);
- структура.
Каждую из этих компонентов подробнее мы рассмотрим далее.
Коллекции данных (Dataframe)
Коллекция данных (dataframe) – это двумерная таблица, которая представляет собой набор данных для дальнейшей обработки и анализа. Большие наборы данных в Spark имеют ряд особенностей, таких как:
- возможность обработки большого размера данных в несколько петабайт;
- поддержка различных форматов данных (CSV, JSON, Avro) и систем хранения данных (MySQL, MS SQL Server, HIVE, HDFS).
- поддержка интерфейса программирования на JAVA, Python, Scala и R
Загрузить файл с расширением .csv в Python можно следующим способом:
csv_data = spark.read.option('header','True').csv('my_file.csv')
Таким образом, переменная csv_data теперь представляет собой коллекцию данных (dataframe).
Структура Spark SQL
Spark SQL – это компонент фреймворка Apache Spark для структурированной обработки данных. Его главная отличительная черта в том, что он способен обрабатывать SQL-запросы на диалекте Hive Query Language (HQL). Основную абстракцию для Спарк SQL составляет датафрейм (dataframe), который упорядочен по именованным столбцам. Внутренний механизм преобразований и вычислений не зависит от языка программирования. Поэтому разработчик может самостоятельно определять интерфейс языка, который наиболее подходит для естественного преобразования. При запуске Spark SQL из другой среды программирования результаты будут возвращены в виде коллекции данных Dataframe. Спарк SQL включает в себя такие особенности, как:
- интеграция – Спарк SQL позволяет запрашивать данные с помощью SQL- запросов в виде распределенной коллекции данных (RDD);
- универсальный доступ к данным – работа со всеми источниками данных происходит по одной и той же схеме, когда доступ к данным происходит через механизм SQL-запросов;
- источники данных – Спарк SQL поддерживает работу с различными источниками данных (например, JSON, Parquet, Hive, JDBC). Существует также возможность смешивать данные из разных источников.
Начало работы со Spark SQL: парочка практических примеров
Для того, чтобы начать работу с модулем Spark SQL, необходимо настроить базовую конфигурацию. Класс SparkSession служит точкой входа для работы со Spark. Поэтому его необходимо импортировать для доступа к функциям Спарк SQL:
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
Теперь нам необходимо создать представление (view) из существующей коллекции данных с помощью метода createOrReplaceTempView:
my_table = csv_data.createOrReplaceTempView('my_table')
Мы получили представление в виде SQL-таблицы. Теперь мы можем работать с ней, используя команды SQL-запросов. Для этого в Spark есть специальный метод sql, который принимает в качестве параметра строку, содержащую SQL-запрос:
sql_table = spark.sql('SELECT * FROM my_table')
А теперь давайте с помощью Spark SQL обработаем датасет, который содержит информацию о твитах (tweets), id которых лежит в диапазоне от 1 до 10:
csv_data = spark.read.option('header','True').csv('my_tweets.csv',sep=',')
my_table = csv_data.createOrReplaceTempView('tweets_table')
sql_table = spark.sql('SELECT Tweet FROM tweets_table WHERE id IN (1,10)')sql_table.show()

Мы видим, что некоторые данные являются отсутствующими, т.е. имеют null-значения. Чтобы удалить эти пропуски, необходимо использовать метод na.drop(), который их удалит:
sql_table = spark.sql('SELECT Tweet FROM tweets_table WHERE id IN (1,10)').na.drop()
sql_table.show()
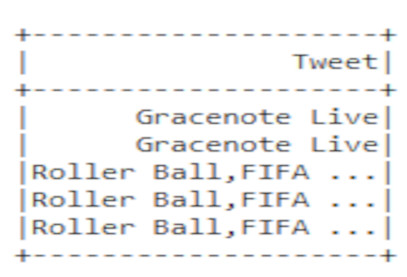
Однако, мы все еще видим дублирующиеся значения. Чтобы их удалить, используется SQL-оператор DISTINCT:
sql_table = spark.sql('SELECT DISTINCT Tweet FROM tweets_table WHERE id IN (1,10)').na.drop()
sql_table.show()

Таким образом, мы обработали датасет с помощью модуля Spark SQL и получили «чистые» данные без дубликатов и пропусков.
Подводя итог всей рассмотренной архитектуре модуля Spark SQL, отметим, что его гибкость и интеграция делают фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы поговорим про другой важный компонент Apache Spark – Spark Streaming.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.

