
В прошлый раз мы говорили про популярные инструменты для сборки распределенных Spark-приложений. Сегодня поговорим про сериализацию данных распределенных приложений, созданных на базе Big Data фреймворка Apache Spark. Читайте далее про особенности механизма сериализации данных Spark-приложений для работы с Big Data в распределенной среде.
Особенности сериализации данных в Apache Spark
Сериализация (serialization) — это перевод данных (структуры данных или объектов) в последовательность байтов (единица хранения и обработки цифровой информации). Механизм сериализации используется в распределенных приложениях при передачи данных по сети (или в пределах вычислительного кластера) [1]. Например, при совместной обработке наборов RDD (Resilient Distributed Dataset) узлы в кластере обмениваются данными между собой для предоставления друг другу информации о последних внесенных изменениях.
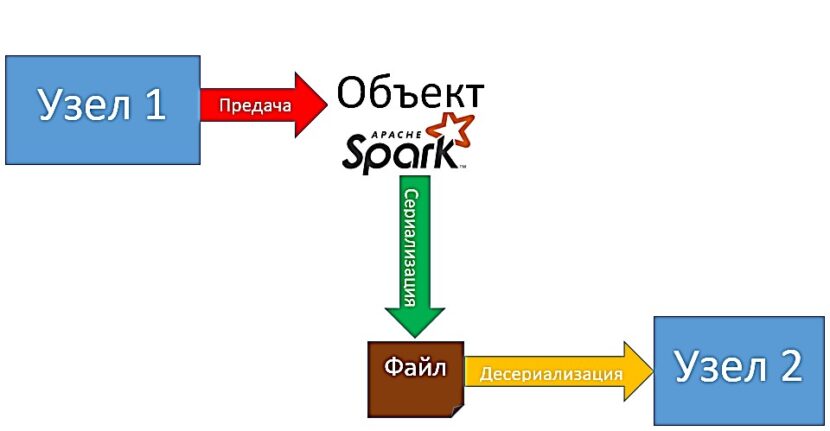
Настройка параметров сериализации Spark-приложений: несколько практических примеров
Параметры сериализации данных Spark-приложения настраиваются при настройке базовой конфигурации среды выполнения (во время запуска Spark-сессии). Следующий код на языке Python задает базовую конфигурацию Spark-приложения и запускает Spark-сессию [2]:
from pyspark.sql import SparkSession
# В качестве примера используется порт по умолчанию (local)
conf = pyspark.SparkConf().setAppName('appName').setMaster('local')
# Развертывапние среды с указанными настройками
sc = pyspark.SparkContext(conf=conf)
# Запуск Spark-сессии
spark = SparkSession(sc)
В вышеописанном фрагменте кода не указаны параметры сериализации данных. В этом случае Spark будет использовать параметры по умолчанию, а именно базовый сериализатор (default pickle serializator). Этот сериализатор можно использовать при обмене небольшим количеством одновременно передаваемых данных (до 100 Мб). В противном случае, скорость передачи может существенно снизиться, что замедлит работу приложения. Для того, чтобы этого избежать, можно использовать специальный маршал-сериализатор (Marshal Serializer), который использует механизм маршалинга (marshaling). Маршалинг — это процесс преобразования данных, которые могут быть переданы по сети, минуя сетевые ограничители (сетевые экраны или балансировщики нагрузки) без потерь путем деления на части (пакеты) и сжатия (для уменьшения размера). За использование маршал-сериализатора отвечает специальный класс MarshalSerializer. Для установки этого сериализатора необходимо передать класс MarshalSerializer в конструктор класса SparkContext как значение поля serializer. Следующий код на языке Python отвечает за установку маршал-сериализатора в качестве основного сериализатора данных приложения [2]:
from pyspark.serializers import MarshalSerializer
sc = SparkContext('local', 'test', serializer=MarshalSerializer())
По умолчанию Spark сериализует объекты, распределяя их по пакетам. Таким образом, чем больше пакетов, тем меньше объектов в каждом из пакетов и тем выше скорость сериализации. Количество пакетов можно задать через поле batchsize в конструкторе класса SparkContext (по умолчанию создается 1024 пакета). Следующий код на языке Python отвечает за установку параметров сериализации с распределением объектов на 800 пакетов [2]:
from pyspark.serializers import MarshalSerializer
sc = SparkContext('local', 'serializationApp', serializer=MarshalSerializer(), batchSize=800)
Таким образом, благодаря поддержке механизма сериализации данных, Spark-приложения могут обмениваться данными в распределенной среде без потерь скорости передачи, а также отдельных частей данных при передаче через сеть, что весьма повышает надежность и скорость этих приложений. Все это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика распределенных Big Data приложений. В следующей статье мы поговорим про управление распределениями в Spark.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники

