В предыдущей статье мы поговорили о разнице между партициями и бакетами Apache Spark. Сегодня на реальном примере покажем, как бакетирование помогает писать оптимизированные запросы без лишних перетасовок.
Что такое бакетирование в Apache Spark?
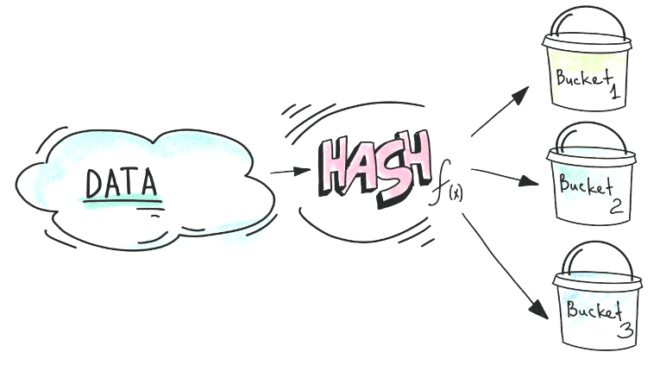
Бакетирование (bucketing) — это метод в Apache Spark и Hive для оптимизации задачи, при котором данные разбиваются на бакеты. Бакетирование помогает избавится от лишней перетасовки (shuffle). При этом бакетами являются кластеризованные столбцы.
При его использовании необходимо определиться с количеством бакетов, т.е. сколько столбцов нужно бакетировать. Во время загрузки будет для каждого такого бакета будет посчитана хэш-значение, или ключ. Для ещё более полной оптимизации можно предварительно разбить на партиции.
У бакектирования есть два основные преимущества:
- Оптимизированный запрос. Во время соединения (join) мы можем явно указать, сколько бакетов будет столбцов. А поскольку бакеты содержат данные одинакового размера, соединения на стороне отображений (map) проходят быстрее, чем небакетированная таблица с бакетированной. Ведь бакет слева будет знать о бакете справа при соединении.
- Предварительное деление на выборки. Поскольку бакетирование уже само по себе предполагает разбиение на части.
Бакетирование включает сортировку и перетасовку данных перед операциями преобразования, например, join. Однако и сортировка, и перетасовка будут выполнены один раз, что исключает расходы на вычислительные ресурсы понапрасну.
Возникает вопрос: на сколько бакетов стоит разбивать датасет? Можно начать с количества, равное числу исполнителей. А дальше уменьшить или увеличить, и проанализировать производительность.
На пример убедимся, что бакетирование не вызывает повторную перетасовку.
Анализ этапов Spark DAG (направленного ациклического графа)
Давайте прочитаем два датасета без применения бакетов и произведем следующие операции: join, groupBy и distinct. Все они производят перетасовку. Ниже приведен код на Scala.
Dataset<Row> mrDS = spark.read().option("header", "true").csv("m-r.csv");
Dataset<Row> mDS = spark.read().option("header", "true").csv("m.csv");
mrDS.join(mDS, "movie_name")
.foreach(new ForeachFunction<Row>() {
@Override
public void call(Row row) throws Exception {}
});
mrDs.grouBy("movie_name").count().show();
mrDs.select("movie_name").distinct().show();
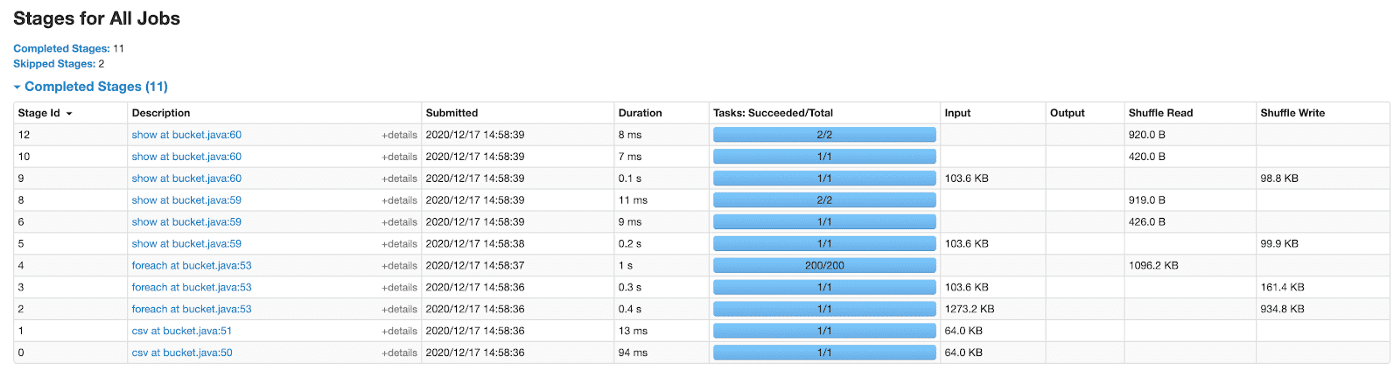
Итак, у нас есть 3 этапа. Для каждого из них была применена перетасовка.
Теперь попробует выполнить то же самое, но перед этим обе таблицы разобьем на бакеты с помощью bucketBy. Выберем количество бакетов, равное 4. Ниже приведен код на Scala.
Dataset<Row> mrDS = spark.read().option("header", "true").csv("m-r.csv");
Dataset<Row> mDS = spark.read().option("header", "true").csv("m.csv");
mrDS.write().mode(SaveMode.Overwrite)
.bucketBy(4, "movie_name")
.saveAsTable("movie_rating");
mDS.write().mode(SaveMode.Overwrite)
.bucketBy(4, "movie_name")
.saveAsTable("movies");
Dataset<Row> mrT = spark.table("movie_rating");
Dataset<Row> mT = spark.table("movies");
mrT.join(mT, "movie_name")
.foreach(new ForeachFunction<Row>() {
@Override
public void call(Row row) throws Exception {}
});
mrT.grouBy("movie_name").count().show();
mrT.select("movie_name").distinct().show();

Как видим, что для каждая операция имеет ровно один этап. Перетасовка выполнилась также один раз при создании бакетированных таблиц (для каждой из них).
Таким образом, мы показали состоятельность использования бакетов при использовании операций преобразований и минимизацию перетасовок (shuffle).
Нужно помнить об ограничениях бакетирования в Spark SQL:
- Бакетирование в Spark SQL различается от бакетирования в Hive, поэтому миграция из Hive в Spark будет дорогостоящей, если данных много;
- Бакетирование требует сортировку данных, что уменьшает производительность;
- Когда Spark записывает данные в бакетирванную таблицу, он может сгенерировать миллионы маленьких файлов, которые не поддерживают в HDFS;
- Оптимальное соединение будет достигнуто только, если таблицы имеют одинаковое число бакетов;
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
21 сентября, 2026
Продолжительность
22 ак.часов
Стоимость обучения
51 200 руб.
О том, как и когда лучше применять бакетирование вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Графовые алгоритмы в Apache Spark

