
Spark обрабатывает данные быстро. Это было основным преимуществом фреймворка с момента его первого представления в 2010 году. Обладая широким спектром вариантов возможностей и простотой использования, Spark быстро стал универсальным фреймворком обработки и анализа больших данных (Big Data). Сегодня мы расскажем о принципах работы Spark и его оптимизаторе Catalyst, который реализует запросы SQL.
Catalyst — оптимизатор запросов
Одним из ключевых компонентов Spark является его модуль SparkSQL, который предлагает возможность выполнять задачи в виде запросов, подобных SQL. За кулисами лежит сложный механизм для выполнения этих запросов. Центральным элементом этого механизма является оптимизатор запросов Catalyst, который выполняет большую часть тяжелой работы, генерируя план физического выполнения задания.
На поверхности лежит DataFrame
Spark предлагает несколько способов взаимодействия со своими интерфейсами SparkSQL, основными из которых являются DataSet и DataFrame. Эти API высокого уровня были построены на основе объектно-ориентированного RDD. Они сохранили его основные характеристики и получили при этом новые функции, например, управление схемами.
Выбор API в основном зависит от используемого языка. DataSet доступен только в Scala/Java, а в Python используется DataFrame. И каждый из них предлагает определенные преимущества. Хорошей новостью является то, что Spark использует тот же движок для выполнения вычислений, поэтому вы можете легко переключаться с одного API на другой. Это означает, что независимо от того, какой API вы используете, когда вы выполняете задачу, она будет проходить единый процесс оптимизации.
Как Spark видит мир
Операции, которые вы можете выполнять в приложении Spark, делятся на два типа:
- Преобразования (Transformations): это операции, которые при применении к RDD возвращают ссылку на новый RDD, созданный посредством преобразования. Некоторые из наиболее часто используемых преобразований — это
filterиmap. - Действия (Actions): При применении к RDD возвращается значение. Например,
countвозвращает количество элементов в RDD драйверной программе, или функцияcollectотправляет данные сами данные.
Операции DataFrame и DataSet разделены на одни и те же категории, поскольку эти API-интерфейсы построены на механизме RDD.
Следующее различие, которое необходимо сделать, — это два типа преобразований, а именно:
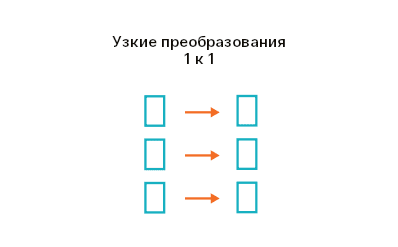
- Узкие преобразования (Narrow transformations) — это когда нет перемещения данных между разделами. Преобразование применяется к данным каждого раздела RDD, и создается новый RDD с тем же числом разделов. Например,
filter— это узкое преобразование, потому что фильтрация применяется к данным каждого раздела, а полученные данные представляют раздел во вновь созданном RDD.
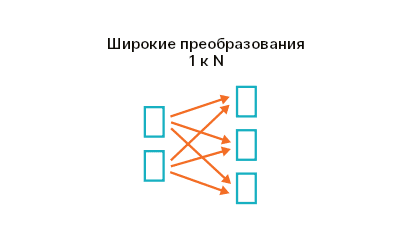
Узкие преобразования - Широкие преобразования (Wide transformations) требуют перемещения данных между разделами или так называемого перемешивания. Данные перемещаются с целью создания нового RDD. Например,
sortByсортирует данные на основе определенного столбца и возвращает новый RDD.
Широкие преобразования
Итак, когда вы отправляете Spark набор неких вычислений, вы отправляете набор действий и преобразований, и, таким образом, формируется плана выполнения задания (этапов вычислений) в оптимизаторе Catalyst. Прежде чем перейти к принципу работы следует понять его типы данных: деревья и правила.
Деревья и правила в Catalyst
Основной тип данных в Catalyst — это дерево, состоящее из узловых объектов. Каждый узел имеет тип и дочерние узлы (а может их не иметь). Новые типы узлов определены в Scala как подклассы класса TreeNode. Эти объекты неизменяемы, и ими можно управлять с помощью функциональных преобразований.
В качестве простого примера предположим, что у нас есть следующие три класса узлов для очень простого языка выражений:
Literal(value: Int): постоянное значениеAttribute(name: String): атрибут из входной строкиAdd(left: TreeNode, right: TreeNode): сумма двух выражений.
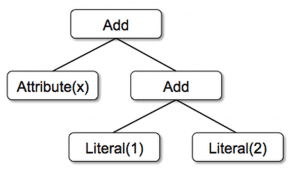
Эти классы можно использовать для построения деревьев; например, дерево для выражения x + (1 + будет представлено в коде Scala следующим образом:
2)
Add(Attribute(x), Add(Literal(1), Literal(2)))
Деревьями можно управлять с помощью правил, которые представляют собой функции от одного дерева к другому. Хотя правило может запускать произвольный код в своем входном дереве, наиболее распространенным подходом является использование функций для поиска по шаблону.
Поиск по шаблону — это особенность функциональных языков программирования, которая позволяет извлекать значения из потенциально вложенных структур алгебраических типов данных. В Catalyst деревья предлагают метод преобразования, который рекурсивно применяет функцию поиска по шаблону ко всем узлам дерева, преобразуя те, которые соответствуют каждому образцу, в соответствующий результат. Например, мы могли бы реализовать правило, которое сворачивает операции сложения между константами следующим образом:
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
}
Применение этого правила к дереву x + (1 + 2) даст новое дерево x + 3.
Отложенные вычисления
Прежде всего, при работе со Spark важно помнить о том, что он полагается на отложенные вычисления. Это означает, что Spark выжидает пока драйверная программа не запустит действие. При каждом вызове действия планировщик Spark строит граф выполнения и запускает задание (Spark job). Задание состоит из этапов, представляющих собой шаги преобразования данных, необходимые для формирования итогового набора RDD. Этап состоит из набора задач (tasks), каждая из которых означает параллельное вычисление, выполняемое на исполнителе.
Вместо того, чтобы запускать преобразования одно за другим, как только он их получает, Spark сохраняет эти преобразования в направленном ациклическом графе (directed acyclic graph, DAG), и как только он получает действие, он запускает весь DAG и доставляет запрошенные выходные данные.
Как работает Catalyst
Spark полагается на оптимизатор Catalyst для выполнения необходимых оптимизаций для создания наиболее эффективного плана выполнения. Catalyst использует конструкции функционального программирования Scala, а также предоставляет библиотеки, специфичные для обработки реляционных запросов.
К узлам дерева Catalyst применяет набор правил для их оптимизации, которая выполняется в четыре этапа, как показано на диаграмме ниже.
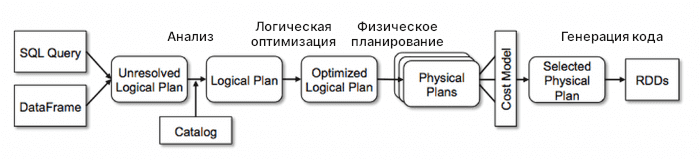
Здесь, логический план составляет дерево, которое описывает, что нужно сделать; тогда как физический план точно описывает, как нужно делать.
Например, логический план просто указывает на то, что необходимо выполнить операцию join, а физический план фиксирует тип соединения (например, ShuffleHashJoin) для этой конкретной операции.
Шаг 1: Анализ
Отправной точкой Catalyst является набор неразрешенных ссылок на атрибуты или отношения. Используете ли вы SQL или DataFrame/Dataset API, модуль SparkSQL поначалу не имеет представления о ваших типах данных или даже о существовании столбцов, на которые вы ссылаетесь (это то, что мы подразумеваем под неразрешенными). Если вы отправляете запрос, SparkSQL сначала будет использовать Catalyst, чтобы определить тип каждого передаваемого столбца и действительно ли существуют столбцы, которые вы используете. Для этого он в основном полагается на деревья и механизмы правил Catalyst.
Сначала он создает дерево для неразрешенного логического плана, затем начинает применять к нему правила, пока не разрешит все ссылки на атрибуты и отношения. На протяжении всего этого процесса Catalyst использует объект Catalog, который отслеживает таблицы во всех источниках данных.
Шаг 2: Логическая оптимизация
С выпуском Spark 2.2 была представлен оптимизатор затрат, который использует статистику и мощности машины для поиска наиболее эффективного плана выполнения вместо простого применения набора правил.
На этом этапе Catalyst применяет все правила оптимизации к логическому плану, оптимизирует затраты, а затем передает оптимизированный логический план к следующему этапу.
Шаг 3: Физический план
Как и в предыдущем шаге, SparkSQL использует для физического планирования Catalyst и оптимизатор затрат. Он генерирует несколько физических планов на основе логического плана для выбора наиболее эффективного из всех предложенных, например, для операции join это может быть ShuffleHashJoin.
Шаг 4: Генерация кода
Заключительный этап оптимизации запросов включает в себя создание байт-кода Java для запуска на каждой машине. Catalyst использует QuasiQuotes, специальную функцию Scala для преобразования дерева задания в абстрактное синтаксическое дерево (AST), которое затем компилирует и запускает сгенерированный код.
В общей сложности генератор кода Catalyst составляет около 700 строк кода.
Spark SQL полагается на сложный конвейер для оптимизации всех ваших вычислений, которые ему необходимо выполнить, и использует Catalyst на всех этапах этого процесса. Этот механизм оптимизации является одной из основных причин высокой производительности Apache Spark в рамках потоковой обработки данных.
В следующей статье мы дадим 3 совета по ускорению обработки данных в Apache Spark. А о том, как на практике применять Spark для обработки больших данных, вы узнаете на специализированном курсе «Потоковая обработка в Apache Spark» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

