В прошлой статье мы говорили о ранжирующей функции ROWS NUMBER в PySpark. Сегодня поговорим о RANK DENSE_RANK, а также узнаем, чем они различаются.
Данные с затонувшего Титаника
Возьмем для примера датасет с затонувшим Титаником. Его можно взять тут. У него много столбцов, поэтому вы покажем только его схему.
df = spark.read.csv("titanic_dataset.csv", header=True, inferScheme=True)
"""
root
|-- PassengerId: integer (nullable = true)
|-- Survived: integer (nullable = true)
|-- Pclass: integer (nullable = true)
|-- Name: string (nullable = true)
|-- Sex: string (nullable = true)
|-- Age: double (nullable = true)
|-- SibSp: integer (nullable = true)
|-- Parch: integer (nullable = true)
|-- Ticket: string (nullable = true)
|-- Fare: double (nullable = true)
|-- Cabin: string (nullable = true)
|-- Embarked: string (nullable = true)
"""
Как использовать RANK в PySpark
Функция RANK вычисляет ранг для каждой партиции. Эта функция очень похожа на ROW NUMBER. Функция ROWS NUMBER нумерует строки последовательно (например, 1, 2, 3, 4). RANK же выдает ранг каждой партиции или порядку, при этом сохраняя внутренний подсчет (например, 1, 2, 2, 4, 4 6).
Поясним это на примере. Определим ранг в PySpark в порядке стоимости билета Fare:
SELECT t.Name, t.Survived, t.Fare,
RANK() OVER(ORDER BY t.Fare) as rnk,
ROW NUMBER() OVER(ORDER BY t.Fare) as rown
FROM titanic t;
"""
+--------------------+--------+------+---+----+
| Name|Survived| Fare|rnk|rown|
+--------------------+--------+------+---+----+
| Leonard, Mr. Lionel| 0| 0.0| 1| 1|
|Harrison, Mr. Wil...| 0| 0.0| 1| 2|
|Tornquist, Mr. Wi...| 1| 0.0| 1| 3|
|"Parkes, Mr. Fran...| 0| 0.0| 1| 4|
|Johnson, Mr. Will...| 0| 0.0| 1| 5|
|Cunningham, Mr. A...| 0| 0.0| 1| 6|
|Campbell, Mr. Wil...| 0| 0.0| 1| 7|
|"Frost, Mr. Antho...| 0| 0.0| 1| 8|
| Johnson, Mr. Alfred| 0| 0.0| 1| 9|
|Parr, Mr. William...| 0| 0.0| 1| 10|
|Watson, Mr. Ennis...| 0| 0.0| 1| 11|
|Knight, Mr. Robert J| 0| 0.0| 1| 12|
|Andrews, Mr. Thom...| 0| 0.0| 1| 13|
| Fry, Mr. Richard| 0| 0.0| 1| 14|
|Reuchlin, Jonkhee...| 0| 0.0| 1| 15|
| Betros, Mr. Tannous| 0|4.0125| 16| 16|
|Carlsson, Mr. Fra...| 0| 5.0| 17| 17|
|Nysveen, Mr. Joha...| 0|6.2375| 18| 18|
|Lemberopolous, Mr...| 0|6.4375| 19| 19|
|Holm, Mr. John Fr...| 0| 6.45| 20| 20|
+--------------------+--------+------+---+----+
"""
Как видим, 16-я строка имеет ранг 16, а не 2.
Этот же запрос для нахождения ранга в PySpark:
import pyspark.sql.functions as F
from pyspark.sql import Window
df.select(
"Name", "Survived", "Fare",
F.rank().over(w).alias("rnk"),
F.row_number().over(w).alias("rown")
)
Мы также можем указать партиции (группы) и считать ранги для каждой партиции и порядка. Например, выдадим ранги по классу пассажира Pclass и убывающему порядку следования стоимости проезда Fare. Такой SQL-запрос формируется следующим образом:
SELECT t.Name, t.Pclass, t.Fare,
RANK() OVER(PARTITION BY Pclass ORDER BY t.Fare DESC) as rnk,
FROM titanic t;
"""
+--------------------+------+--------+---+
| Name|Pclass| Fare|rnk|
+--------------------+------+--------+---+
| Ward, Miss. Anna| 1|512.3292| 1|
|Cardeza, Mr. Thom...| 1|512.3292| 1|
|Lesurer, Mr. Gust...| 1|512.3292| 1|
|Fortune, Mr. Char...| 1| 263.0| 4|
|Fortune, Miss. Ma...| 1| 263.0| 4|
|Fortune, Miss. Al...| 1| 263.0| 4|
| Fortune, Mr. Mark| 1| 263.0| 4|
|Ryerson, Miss. Em...| 1| 262.375| 8|
|"Ryerson, Miss. S...| 1| 262.375| 8|
|Baxter, Mr. Quigg...| 1|247.5208| 10|
|Baxter, Mrs. Jame...| 1|247.5208| 10|
|Bidois, Miss. Ros...| 1| 227.525| 12|
| Robbins, Mr. Victor| 1| 227.525| 12|
|Astor, Mrs. John ...| 1| 227.525| 12|
|Endres, Miss. Car...| 1| 227.525| 12|
| Farthing, Mr. John| 1|221.7792| 16|
|Widener, Mr. Harr...| 1| 211.5| 17|
|Madill, Miss. Geo...| 1|211.3375| 18|
|Allen, Miss. Elis...| 1|211.3375| 18|
|Robert, Mrs. Edwa...| 1|211.3375| 18|
+--------------------+------+--------+---+
"""
Чтобы указать убывающий порядок в самом PySpark, то лучше всего это сделать через функцию desc:
w = Window.partitionBy("Pclass").orderBy(F.desc("Fare"))
df.select(
"Name", "Pclass", "Fare",
F.rank().over(w).alias("rnk")
)
Use case: взять самые высокие значения по каждой группе
Вдруг нам понадобилось взять первые N значений (наименьших или наибольших) в каждой группе. Мы можем это сделать так же, как это делали с ROW NUMBER в предыдущей статье, т.е. через подзапрос и обычный фильтр.
Например, SQL-запрос возьмем пассажиров из каждого класса, которые заплатили больше всего,
SELECT * FROM (
SELECT t.Name, t.Pclass, t.Fare,
RANK() OVER(PARTITION BY Pclass ORDER BY t.Fare) AS rnk
FROM titanic t
) x
WHERE x.rnk < 4;
"""
+--------------------+------+--------+---+
| Name|Pclass| Fare|rnk|
+--------------------+------+--------+---+
| Ward, Miss. Anna| 1|512.3292| 1|
|Cardeza, Mr. Thom...| 1|512.3292| 1|
|Lesurer, Mr. Gust...| 1|512.3292| 1|
|Sage, Master. Tho...| 3| 69.55| 1|
|Sage, Miss. Const...| 3| 69.55| 1|
| Sage, Mr. Frederick| 3| 69.55| 1|
|Sage, Mr. George ...| 3| 69.55| 1|
|Sage, Miss. Stell...| 3| 69.55| 1|
|Sage, Mr. Douglas...| 3| 69.55| 1|
|"Sage, Miss. Doro...| 3| 69.55| 1|
|Hood, Mr. Ambrose Jr| 2| 73.5| 1|
|Hickman, Mr. Stan...| 2| 73.5| 1|
|Davies, Mr. Charl...| 2| 73.5| 1|
|Hickman, Mr. Leon...| 2| 73.5| 1|
| Hickman, Mr. Lewis| 2| 73.5| 1|
+--------------------+------+--------+---+
"""
То же самое в PySpark:
w = Window.partitionBy("Pclass").orderBy(F.desc("Fare"))
x = df.select(
"Name", "Pclass", "Fare",
F.rank().over(w).alias("rnk")
)
x.where("rnk < 4").show()
RANK vs DENSE RANK в PySpark
Apache Spark поддерживает еще и DENSE RANK. В отличие от обычного RANK он выдает ранг группам последовательно (1, 2, 3, 4, 5). Например, выведем оба ранга:
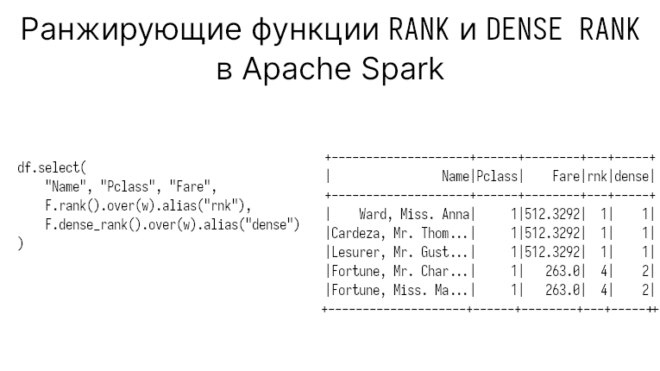
df.select(
"Name", "Pclass", "Fare",
F.rank().over(w).alias("rnk"),
F.dense_rank().over(w).alias("dense")
)
"""
+--------------------+------+--------+---+-----+
| Name|Pclass| Fare|rnk|dense|
+--------------------+------+--------+---+-----+
| Ward, Miss. Anna| 1|512.3292| 1| 1|
|Cardeza, Mr. Thom...| 1|512.3292| 1| 1|
|Lesurer, Mr. Gust...| 1|512.3292| 1| 1|
|Fortune, Mr. Char...| 1| 263.0| 4| 2|
|Fortune, Miss. Ma...| 1| 263.0| 4| 2|
|Fortune, Miss. Al...| 1| 263.0| 4| 2|
| Fortune, Mr. Mark| 1| 263.0| 4| 2|
|Ryerson, Miss. Em...| 1| 262.375| 8| 3|
|"Ryerson, Miss. S...| 1| 262.375| 8| 3|
|Baxter, Mr. Quigg...| 1|247.5208| 10| 4|
|Baxter, Mrs. Jame...| 1|247.5208| 10| 4|
|Bidois, Miss. Ros...| 1| 227.525| 12| 5|
| Robbins, Mr. Victor| 1| 227.525| 12| 5|
|Astor, Mrs. John ...| 1| 227.525| 12| 5|
|Endres, Miss. Car...| 1| 227.525| 12| 5|
| Farthing, Mr. John| 1|221.7792| 16| 6|
|Widener, Mr. Harr...| 1| 211.5| 17| 7|
|Madill, Miss. Geo...| 1|211.3375| 18| 8|
|Allen, Miss. Elis...| 1|211.3375| 18| 8|
|Robert, Mrs. Edwa...| 1|211.3375| 18| 8|
+--------------------+------+--------+---+-----+
"""
На 4-й строке плотный ранг дал строке значение 2, а не 4, как это делает обычный ранг.
А в следующей статье поговорим о функциях LEAD и LAG. Еще больше подробностей о оконных функциях в PySpark вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и IT-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Код курса
MLSP
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков

