
В прошлый раз мы говорили деревья решений в Spark. Сегодня поговорим о том, как устроена распределенная архитектура Big Data фреймворка Apache Spark. Читайте далее про архитектуру среды Spark и ее особенности, включая основные элементы, из которых она состоит.
Как работает распределенная среда Spark: основные особенности архитектуры
Приложения, которые создаются на базе фреймворка Spark, предназначены для работы в распределенной среде (например, в кластере, состоящем из нескольких узлов). Архитектура распределенной (параллельной) среды включает в себя следующие компоненты:
- драйвер Spark;
- Spark-исполнители.
Каждый из этих элементов мы подробнее рассмотрим далее.
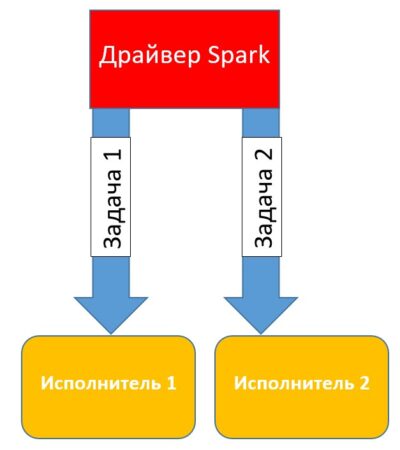
Драйвер Spark
Драйвер Spark — это процесс, который распределяет задачи, поступающие от пользователя по действующим исполнителям. Таким образом, Spark-драйвер преобразует пользовательское приложение на единицы исполнения, которые называются задачи (tasks). Экземпляр Spark-драйвера запускается во время запуска сессии (драйвер Spark создает сессию) Spark при первом запуске приложения и остается активным до тех пор, эта сессия активна (приложение работает и сбой не произошел). Следующий код на языке Python отвечает за запуск драйвера Spark [1]:
conf = pyspark.SparkConf().setAppName('MyApp').setMaster('local')
sc = pyspark.SparkContext(conf=conf)
#запуск Spark-драйвера
spark = SparkSession(sc)
Во время запуска драйвера ему выделяется определенное количество оперативной памяти (по умолчанию 1Гб). Разработчик может самостоятельно изменить объем выделяемой оперативной памяти с помощью метода config(). Для этого метода используется параметр spark.driver.memory:
spark = SparkSession.builder\
.config ("spark.driver.memory", "16g")\
.getOrCreate()
Приложение может разбиваться на несколько сотен и даже тысяч заданий (в зависимости от функционала). На основе составленного плана со всеми задачами драйвер Spark контролирует передачу этих задач исполнителям. При запуске каждый исполнитель регистрирует себя в драйвере.
Spark-исполнители
Spark-исполнители (Spark executors) — это рабочие процессы, которые отвечают за выполнение задач, приходящих из драйвера. Исполнители запускаются только один раз при запуске приложения Spark и продолжают свою работу на протяжении всего жизненного цикла программы. Они выполняют задачи, приходящие от драйвера и возвращают результат обратно драйверу Spark. Каждому исполнителю, также, как и драйверу выделяется определенный объем оперативной памяти, значение которого по умолчанию составляет 1Гб. Каждый исполнитель имеет определенное число ядер (cores). Ядро исполнителя (executor core) отвечает за параллельное выполнение задач одним исполнителем [1].
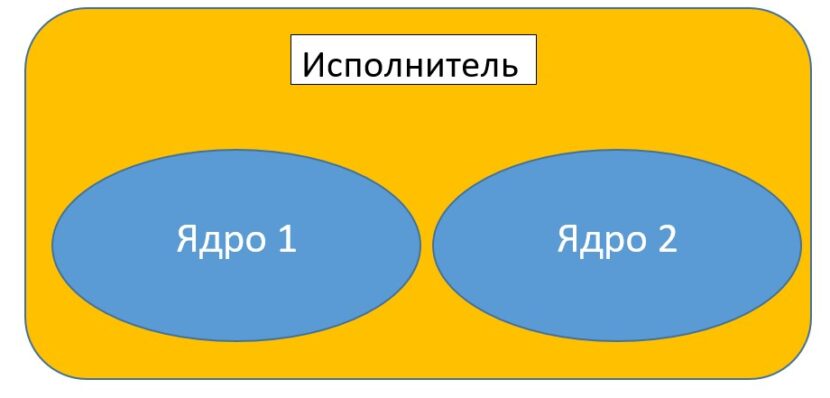
Чем больше количество ядер, тем больше задач может одновременно выполнять один исполнитель. Однако стоит контролировать количество ядер в каждом исполнителе, так как каждое ядро требует значительных затрат мощности процессора. Слишком большое количество ядер может привести к сбою приложения. Следующий код на языке Python отвечает за настройку конфигурации Spark-исполнителей [2]:
spark = SparkSession.builder\
# Количество исполнителей
.config("spark.executor.instances", "4")\
# Память для каждого исполнителя
.config("spark.executor.memory", "2g")\
#Количество ядер для каждого исполнителя
.config('spark.executor.cores','2')
Таким образом, распределенная архитектура приложения Spark позволяет выполнять большие объемы Big Data задач, требующих высокое количество вычислений. Все это делает framework Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы поговорим про управление распределениями в Spark.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники
- К.Харау, Э.Ковински, П.Венделл, М.Захария. Изучаем Spark: молниеносный анализ данных
- https://spark.apache.org/docs/latest/configuration.html#memory-management

