
В прошлый раз мы говорили про особенности обработки файлов JSON в Spark. Сегодня поговорим про деревья решений в распределенном фреймворке Apache Spark. Читайте далее про особенности ML-алгоритма деревьев решений в Spark и их особенности.
Как работают деревья решений в Spark: основные особенности
Дерево решений (decision tree) — это алгоритм принятия решений, основанный на структуре «листьев» и «веток». На ветках дерева записаны признаки (features), от которых зависит целевая функция (функция, использующаяся для решения конкретной задачи), а в листьях дерева записаны значения целевой функции при прохождении некоторого набора признаков (веток) [1].
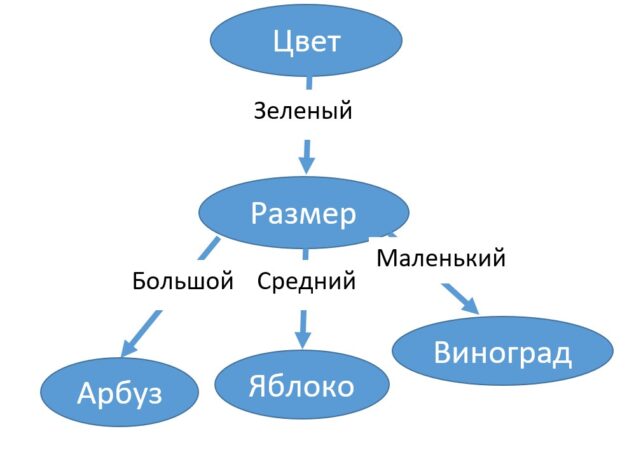
Работа с деревом решений в Spark: несколько практических примеров
Для того, чтобы начать работу с деревом решений, необходимо настроить базовую конфигурацию приложения, импортировав необходимые библиотеки:
# импорт алгоритма модели дерева решений from pyspark.ml.classification import DecisionTreeClassifier #импорт библиотек для работы с категориальными данными from pyspark.ml.feature import OneHotEncoderEstimator, StringIndexer, VectorAssembler # Pipeline для последовательности преобразований и обучения модели from pyspark.ml import Pipeline #Оценка модели from pyspark.ml.evaluation import BinaryClassificationEvaluator
Далее необходимо запустить сессию Spark и создать датафрейм, прочитав его из файла с датасетом банковского маркетинга bank.csv, который можно скачать здесь:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('decision_tree').getOrCreate()
df = spark.read.csv('bank.csv', inferSchema=True,header=True)
Для прогноза необходимо определить признаки, в качестве которых выступают колонки датафрейма, значения которых будет использоваться в модели. Следующий код на языке Python отвечает за формирование набора признаков, целевой переменной (значение которой нужно предсказать) является колонка deposit:
df = df.select('age', 'job', 'marital', 'education', 'default', 'balance', 'housing', 'loan','contact', 'duration', 'campaign', 'pdays', 'previous', 'poutcome', 'deposit')
cols = df.columns
Для подготовки данных используется OneHotEncoder (для преобразования всех значений в категориальный тип) и VectorAssembler (для формирования вектора признаков):
сategoricalColumns = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'poutcome'] stages = [] for categoricalCol in categoricalColumns: stringIndexer = StringIndexer(inputCol = categoricalCol, outputCol = categoricalCol + 'Index') encoder = OneHotEncoderEstimator(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"]) stages += [stringIndexer, encoder] label_stringIdx = StringIndexer(inputCol = 'deposit', outputCol = 'label') stages += [label_stringIdx] numericCols = ['age', 'balance', 'duration', 'campaign', 'pdays', 'previous'] assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features") stages += [assembler] pipeline = Pipeline(stages = stages) pipelineModel = pipeline.fit(df) df = pipelineModel.transform(df) selectedCols = ['label', 'features'] + cols df = df.select(selectedCols)
Для загрузки подготовленных данных в модель их необходимо разбить на тренировочную (70%) и тестовую (30%) выборки:
train, test = df.randomSplit([0.7, 0.3])
Остаётся только обучить дерево решений и оценить его точность. В качестве метрики качества модели используется TAUR (Test Area Under ROC (Receiver Operating Characteristic)), которая оценивает точность модели дерева решений на тестовой выборке:
dt = DecisionTreeClassifier(featuresCol = 'features', labelCol = 'label', maxDepth = 8)
dtModel = dt.fit(train)
predictions = dtModel.transform(test)
evaluator = BinaryClassificationEvaluator()
print("Test Area Under ROC: " + str(evaluator.evaluate(predictions, {evaluator.metricName: "areaUnderROC"})))
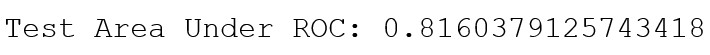
Таким образом, параллельность алгоритмов машинного обучения библиотеки Spark MLlib позволяет обрабатывать наборы Big Data с весьма высокой скоростью. Все это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы поговорим про архитектуру распределенной среды Spark.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники

