
В прошлый раз мы говорили про особенности работы алгоритма многослойного персептрона в Spark. Сегодня поговорим про алгоритм градиентного бустинга (GBT) в распределенном Big Data фреймворке Apache Spark. Читайте далее про особенности работы алгоритма GBT, благодаря которому Apache Spark имеет возможность Big Data анализа и классификации в распределенной среде.
Как работает алгоритм GBT в Spark: особенности классификации
GBT (Gradient Boost Tree) — это алгоритм машинного обучения, использующийся для задач классификации и регрессии, который строит модель предсказания величины в форме ансамбля слабых предсказывающих моделей, в частности деревьев решений. Обучение модели основано на обучении с учителем. Цель любого алгоритма обучения с учителем — это определение функции потерь и ее минимизация Ансамбль представляет собой набор предсказателей, которые дают общий ответ. Ансамбли используют обычно для более точного предсказания одной и той же переменной. Существуют 2 техники ансамблирования: бэггинг и бустинг. Бэггинг – это техника, которая основана на построении независимых (некоррелирующих) моделей и их комбинировании путем усреденения (например, взвешенное среднее или голосование большинства) Примером бэггинга может служить модель случайного леса. Бустинг – это техника построения ансамблей, в которой предсказатели построены последовательно, а каждая следующая модель будет учиться на ошибках предыдущей. Наиболее яркий пример бустинга – это градиентный бустинг [1].
GBT-алгоритм в Spark: несколько практических примеров
Для того, чтобы начать работу с GBT-алгоритмом в pyspark, необходимо настроить базовую конфигурацию, импортировав некоторые классы ml-библитоеки Spark [2]:
from pyspark.ml.classification import GBTClassifier from pyspark.ml.evaluation import MulticlassClassificationEvaluator from pyspark.ml.feature import VectorAssembler
В качестве датасета будем использовать данные о кредитовании, в котором каждая запись представляет хорошего (creditability=1) и плохого (creditability=0) заемщика на основании его личных данных (например, возраст, кредитная история, сумма кредита и т.д.). Датасет можно сказать из источника здесь.
В первую очередь необходимо прочитать датасет с помощью pyspark [2]:
inputData = spark.read.csv("credit.csv", inferSchema=True, header=True)
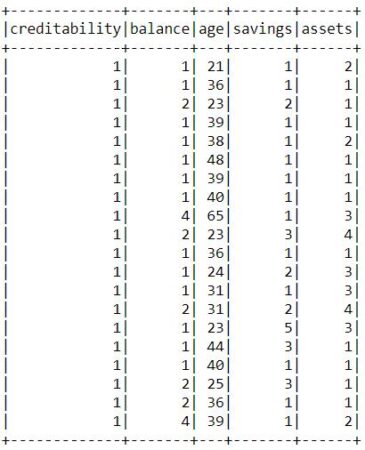
Далее необходимо сформировать вектор признаков путем их векторизации с помощью класса VectorAssembler. Векторизованные признаки назовем features [2]:
assembler = VectorAssembler( inputCols=["amount", "savings", "assets", "age", "credits"], outputCol="features") output = assembler.transform(inputData)
После векторизации необходимо разбить выборку на обучающую и тестовую (стандартно, 70:30 соответственно). Для того, чтобы случайным образом разбить датасет на тестовую и тренировочную выборки, необходимо использовать метод randomSplit() [2]:
train, test = output.randomSplit([0.7, 0.3])
Для построения GBT-модели в pyspark используется класс GBTClassifier:
gbt = GBTClassifier(labelCol="creditability", featuresCol="features", maxIter=10)
В качестве параметров конструктора класса у экземпляра GBTClassifier() используются следующие:
featuresCol— колонка, содержащая вектор признаков, на основе которых ведется предсказание или классификация;labelCol— колонка целевой переменной, для которой идет предсказание (классификация)maxIter— количество итераций при обучении модели [2].
Для обучения построенной модели используется метод fit() [2]:
model = gbt.fit(train)
Для предсказания (или классификации) используется метод transform(). Следующий код на языке Python отвечает за формирование датасета с предсказаниями [2]:
predictions = model.transform(test)
В качестве оценщика будем использовать оценщик мультиклассовой классификации MulticlassClassificationEvaluator с метрикой accuracy. За формирование оценки модели отвечает метод evaluate() класса MulticlassClassificationEvaluator [2]:
evaluator = MulticlassClassificationEvaluator(
labelCol="creditability", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(predictions)
print("Test Error = %g" % (1.0 - accuracy))
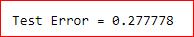
Таким образом, благодаря поддержке алгоритма случайных лесов, Spark имеет возможность проводить классификацию в распределенной среде, используя огромные массивы данных для обучения, что может способствовать обучению весьма эффективных моделей. Все это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений.
Код курса
GRAS
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Разработка и внедерение ML-решений
- Графовые алгоритмы. Бизнес-приложения
Источники

