
Сегодня поговорим о том, какие наиболее распространенные форматы файлов способен поддерживать фреймворк Apache Spark. Также рассмотрим, как эффективно сохранять данные в этих форматах. Читайте далее, чтобы узнать какие файлы поддерживает Spark.
Какие файлы наиболее распространены в Spark: 3 самых известных формата
Фреймворк Spark может работать с данными, которые загружаются из различных файлов. Для доступа к данным Spark использует интерфейсы InputFormat и OutputFormat, которые поддерживают множество форматов файлов (CSV, JSON, XLS, TXT и т.д) и систем хранения данных (Apache Hadoop HDFS, Amazon S3, Cassandra, HBase). В этой статье мы поговорим о следующих наиболее известных форматах файлов в Spark:
- CSV;
- JSON;
- текстовые форматы данных.
Каждый из них мы подробнее рассмотрим далее.
Текстовые файлы
Текстовый формат данных – это файлы, содержимое которых воспринимается как набор строк с текстовыми значениями. Когда текстовый файл используется как источник данных, Spark интерпретирует каждую его строку как отдельный элемент набора RDD. Чтобы загрузить данные в текстовом формате используется метод textFile:
my_text=sc.textFile('my_tweets.csv')
type(my_text) ##pyspark.rdd.RDD
Итак, метод textFile() преобразовал данные в распределенный набор RDD независимо от его расширения.
А теперь рассмотрим, как происходит сохранение RDD в текстовый формат:
typic_rdd = sc.parallelize([1,2,3,4,5,6,7,8])
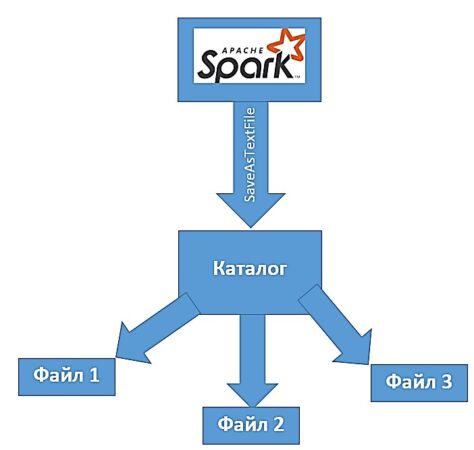
typic_rdd.saveAsTextFile('my_text')
Метод saveAsTextFile() создает новый каталог и помещает туда множество файлов с содержимым RDD. Такой подход дает возможность сохранять данные с нескольких узлов одновременно.
Работа с JSON-файлами
JSON (JavaScript Object Notation – объектная нотация JavaScript) – это текстовый формат данных, который хранит информацию в виде структуры ключ/значение. Чтобы загрузить JSON-файл в Spark, необходимо его сначала прочитать как текстовый файл, а затем отобразить данные в значения с помощью парсера JSON json.loads:
my_json=sc.textFile('my_json_rdd.json')
import json
data = my_json.map(lambda x: json.loads(x))
Как мы можем заметить, при загрузке данных JSON мы снова получаем набор RDD. Запись данных в JSON-формат осуществляется намного проще, чем загрузка, так как нам не нужно беспокоиться об ошибках при форматировании. К тому же мы точно знаем тип выгружаемых данных. Благодаря структуре RDD мы можем сразу сохранять отфильтрованные JSON-данные:
data.filter(lambda x: x['1013597044198391808'])\
.map(lambda x: json.dumps(x))\
.saveAsTextFile('ouput_data')
Формат CSV
Формат CSV (Comma-Separated Values – данные, разделенные запятой) – это данные, которые представляют собой набор значений, разделенных специальным разделителем (как правило, запятой). Такие файлы содержат фиксированное число полей в каждой строке. Таким образом CSV-файл можно представить в виде таблицы с данными. Этот тип файлов можно загружать в виде текста, как рассматривалось выше, а можно – в виде датафрейма через специальный метод read.csv():
csv_data = spark.read.option('header','True').csv('my_tweets.csv',sep=',')
type(csv_data)##pyspark.sql.dataframe.DataFrame
Метод read.csv() загрузил наши данные и создал датафрейм. Теперь можно обрабатывать данные и применять к нему методы для работы с датафреймами.
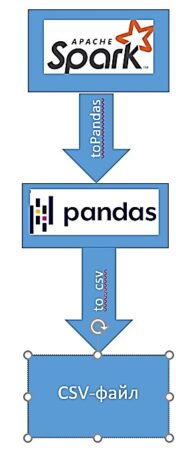
Поскольку анализируемые данные представляют собой Spark-датафрейм, для более удобного сохранения их можно перевести его в Pandas-датафрейм с помощью метода toPandas() и напрямую сохранить в формате CSV:
pandas_data=csv_data.toPandas()
pandas_data.to_csv('new_data.csv')
Таким образом, Apache Spark позволяет без проблем работать с различными видами файлов, что делает его весьма полезным инструментом для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы поговорим про основные функции для работы с датафреймами Spark.
Более подробно про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.

