В прошлый раз мы говорили об основных операциях над графами GraphFrames в Apache Spark. Сегодня рассмотрим поиск по шаблону (motif finding). Что такое motif finding, как задается в GraphFrames, какие правила и ограничения, всё это с примерами в нашей статье.
Что такое поиск по шаблону, или motif finding
Поиск по шаблону (morif finding) — это способ нахождения заданных структурных шаблонов в графе. В GraphFrames для поиска по шаблону используется свой очень простой предметно-ориентированный язык для выражения запросов к графу. Запрос с шаблоном передается методу find. Например, запрос:
graph.find("(a)-[e]->(b); (b)-[e2]->(a)")
— найдет все подграфы, состоящие из двух вершин a и b, которые соединены друг с другом в обоих направлениях. Результатом запроса будет DataFrame со столбцами a, e, b, e2, где e и e2 — ребра. Все эти столбцы имеют тип StructField, который эквивалентен исходному датфрейму вершин или ребер.
К сожалению, GraphFrames не предоставляет выбора алгоритма поиска, хотя их существует огромное множество [1].
Правила шаблонов
Шаблоны с запросом к графу GraphFrame должны удовлетворять следующим условиям [2]:
- Вершины должны быть заключены в круглые скобки, ребра — в квадратные. Имена результирующих столбцов будут такие же, какие имена заключены в скобках.
- Единицей шаблона является ребро. Ребра разделяются точкой с запятой. Направление у связи всегда правое (знак больше): (откуда)-[ребро]->(куда). Например, шаблон
(a)-[e]->(b); (b)-[e2]->(c)обозначает связьaдоbиbдоc. Шаблоны(a)-[e]->(b)-[e2]->(c)и(a)<-[e]->(b)НЕ допустимы. - Разрешается опускать названия ребер и/или вершин. Например, шаблон
(a)-[]->(b)выражает связь междуaиb, в результирующем датафрейме столбцаeне будет; а в шаблоне(a)-[]->()будут опущены и ребро, и вершина, в которую входит ребро. Такие вершины и ребра называются анонимными. - Связь может содержать отрицание через
!. Таким образом обозначается, что связь не должна присутствовать в графе. Например,(a)-[]->(b); !(b)-[]->(a)соответствует тем связям, в котором есть путь изaвb, но нет пути изbвa. - Имена не обозначают уникальные компоненты. Например, в шаблоне
(a)-[e]->(b); (b)-[e2]->(c)именаaиcмогут относится к одной и той же вершине. Чтобы получить уникальные значения, отфильтруйте результирующий DataFrame, например, вот такres.filter("a.id != c.id").
При этом у шаблонов есть ограничения:
- В шаблоне не должны все элементы быть анонимными. Поэтому шаблон
()-[]->()и!()-[]->()запрещены. - Шаблон с отрицанием не должен иметь именованное ребро. Поэтому шаблон
!(a)-[ab]->(b)неправильный, а шаблон!(a)-[]->(b)— правильный.
Пример использования поиска по шаблону
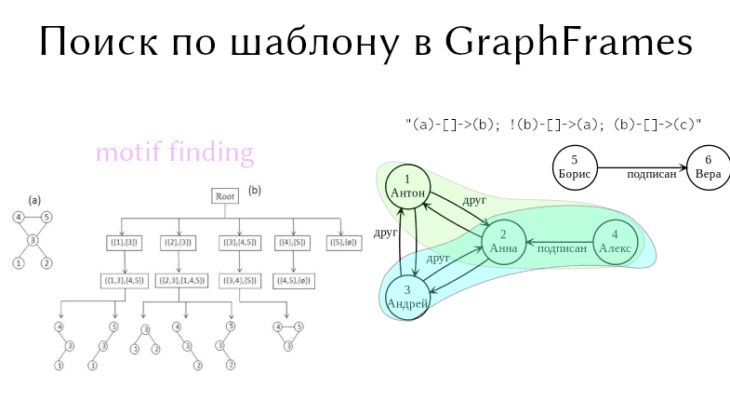
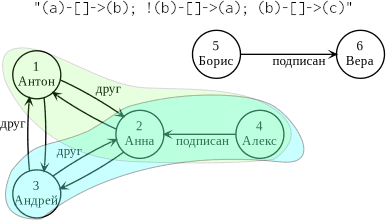
Воспользуемся тем же графом, который мы создали в прошлой статье. Итак, найдем те подграфы GraphFrame, состоящие из 3 вершин, где первые две имеют только прямой путь, а обратного нет (см. рисунок ниже). Запрос по такому шаблону в Apache Spark будет следующим:
>>> motif = g.find("(a)-[]->(b); !(b)-[]->(a); (b)-[]->(c)")
>>> motif.show()
+-------------+-------------+--------------+
| a| b| c|
+-------------+-------------+--------------+
|[4, Alex, 32]|[2, Anna, 27]|[1, Anton, 23]|
|[4, Alex, 32]|[2, Anna, 27]|[3, Andry, 24]|
+-------------+-------------+--------------+
Поскольку результатом поиска по шаблону является DataFrame, то к нему можно применять методы фильтрации:
>>> motif.filter("c.age > 23").show()
+-------------+-------------+--------------+
| a| b| c|
+-------------+-------------+--------------+
|[4, Alex, 32]|[2, Anna, 27]|[3, Andry, 24]|
+-------------+-------------+--------------+
Поиск по шаблону Graphframes с условием
Приведенный выше пример достаточно прост. Поиск по шаблону отбирает те подграфы, у которых есть та или иная связь, соответствующая этому шаблону. Дело усложняется, когда заходит речь о фильтрации по атрибутам (столбцам) вершины или ребра. Поэтому приходится отбирать нужные значения самостоятельно.
Рассмотрим пример. Допустим, требуется найти подграфы, которые состоят из 3 вершин и имеют в своей связи как минимум 2 друзей. Тогда нам понадобится:
- отобрать все подграфы с тремя вершинами;
- определить функцию по подсчету друзей;
- применить эту функцию к ребрам;
- указать условие для отбора.
Ниже приведен код для нахождения тех связей в графе GraphFrames, которые удовлетворяют заданному условию (имеют более чем 2 друзей). Мы использовали функцию reduce, которая применит к ребрам заданную функцию [3].
import pyspark.sql.functions as F
chain3 = g.find("(a)-[ab]->(b); (b)-[bc]->(c)")
# Если `friend`, то +1, если нет, то оставь так
count_friends = (lambda n, relation:
F.when(relation == "friend", n+1).otherwise(n)
)
# Применить функцию для столбцов `ab` и `bc`.
# `lit(0)` задает начальное значение в 0
cond = (reduce(lambda n, e:
count_friends(n, F.col(e).type), ["ab", "bc"], F.lit(0))
)
chain3.where(cond > 1).show()
+--------------+--------------+--------------+--------------+--------------+ | a| ab| b| bc| c| +--------------+--------------+--------------+--------------+--------------+ |[1, Anton, 23]|[1, 3, friend]|[3, Andry, 24]|[3, 1, friend]|[1, Anton, 23]| | [2, Anna, 27]|[2, 3, friend]|[3, Andry, 24]|[3, 1, friend]|[1, Anton, 23]| |[1, Anton, 23]|[1, 2, friend]| [2, Anna, 27]|[2, 1, friend]|[1, Anton, 23]| |[3, Andry, 24]|[3, 2, friend]| [2, Anna, 27]|[2, 1, friend]|[1, Anton, 23]| |[3, Andry, 24]|[3, 1, friend]|[1, Anton, 23]|[1, 3, friend]|[3, Andry, 24]| | [2, Anna, 27]|[2, 1, friend]|[1, Anton, 23]|[1, 3, friend]|[3, Andry, 24]| |[1, Anton, 23]|[1, 2, friend]| [2, Anna, 27]|[2, 3, friend]|[3, Andry, 24]| |[3, Andry, 24]|[3, 2, friend]| [2, Anna, 27]|[2, 3, friend]|[3, Andry, 24]| |[3, Andry, 24]|[3, 1, friend]|[1, Anton, 23]|[1, 2, friend]| [2, Anna, 27]| | [2, Anna, 27]|[2, 1, friend]|[1, Anton, 23]|[1, 2, friend]| [2, Anna, 27]| |[1, Anton, 23]|[1, 3, friend]|[3, Andry, 24]|[3, 2, friend]| [2, Anna, 27]| | [2, Anna, 27]|[2, 3, friend]|[3, Andry, 24]|[3, 2, friend]| [2, Anna, 27]| +--------------+--------------+--------------+--------------+--------------+
Недостатком поиска по шаблону является задание фиксированной длины графа. К счастью, можно всегда переиспользовать код. Кроме того, можно придумать свой скрипт, который будет генерировать последовательность, например, такая функция на Python:
from string import ascii_lowercase as a
def format_path(alph_idx):
return "({})-[{}]->({}); ".format(
a[alph_idx], a[alph_idx] + a[alph_idx+1], a[alph_idx+1]
)
def generate_motif_finding(n):
if n > 25:
print("Too much vertices, use `ascii_letters`")
return
"".join([format_path(i) for i in range(n)])[:-2]
В следующей статье расскажем о том, как перевести граф GraphFrames в рисунки формата PNG и визуализировать их в Jupyter Notebook. Ещё больше подробностей о motif finding вы узнаете на специализированном курсе по машинному обучению «Графовые алгоритмы в Apache Spark» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

