Иногда приходится работать с несколькими связанными таблицами сразу, причем требуется их каким-то образом соединять. В этом случае вам поможет операция JOIN в PySpark. Сегодня расскажем о INNER, LEFT, RIGHT и FULL JOIN, а также об особенности его применения.
Две таблицы
Допустим, имеется две таблицы. Первая таблицы с сотрудниками:
emp_data = [
(1, "Alexander", 2, 3500),
(2, "Roman", 1, 4500),
(3, "Tom", 1, 5500),
(4, "Alex", 3, 3000),
(5, "Arthur", 4, 4250),
(6, "Anna", 4, 3520),
(7, "Svetlana", 2, 3000),
(8, "Oleg", 5, 3200),
(9, "Felix", 1, 5500),
(10, "Olga", 5, 4970),
(11, "Anna", 4, 6320),
(12, "Tom", 3, 3500),
(13, "Felix", 4, 3520),
(14, "John", 2, 3500),
(15, "Finn", 5, 5570),
(16, "Polly", 3, 3800),
]
emp_schema = ["emp_id", "emp_name", "dept_id", "salary"]
emp = spark.createDataFrame(emp_data, emp_schema)
Вторая таблица с отделами:
dept_data = [
(1, "IT"),
(2, "Admin"),
(3, "HR"),
(4, "Finance"),
(6, "Marketing"),
]
dept_schema = ["dept_id", "dept_name"]
dept = spark.createDataFrame(dept_data, dept_schema)
Если мы еще раз взглянем на них. Ольга, Олег и Финн находятся в отделе под номером 5. Так вот во второй таблице нет отдела с таким номером. Но в ней есть отдел под номером 6, в который никто из сотрудников не входит. Эти знания нам пригодятся для изучения JOIN.
Синтаксис JOIN в PySpark
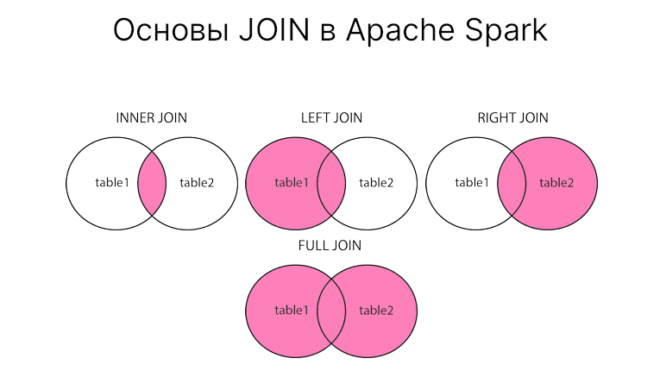
JOIN необходим для соединения нескольких таблиц. Есть следующие типы JOIN’ов:
INNER JOINLEFT [ OUTER ] JOINRIGHT [ OUTER ] JOINFULL [ OUTER ] JOINCROSS JOIN
В классическом SQL внутренние соединения строится из предложений FROM или WHERE. Внешние и перекрестные соединения строятся только из FROM. Например, вот так выглядит внутреннее соединение в SQL:
SELECT e.emp_name, d.dept_name FROM employee e JOIN department d ON e.dept_id == d.dept_id
В PySpark соединения строятся из метода join, где первым параметром передается таблица для соединения, вторым — то самое условие ON, третьим — тип соединения (по умолчанию inner) [1].
INNER JOIN
Допустим нам нужно определить название отделов, в которые входят сотрудники. Как видим, в первой таблице даны только их номера. INNER JOIN выбирает записи из обеих таблиц только в том случае, если существует точные совпадения между ними. Так, например, 3 сотрудника состоят в неизвестном отделе, поскольку совпадений между ними и второй таблицей нет, то они не будут выбраны.
Итак, INNER JOIN в PySpark будет выглядеть одним из следующих образов:
# Некоторые способы вызова join. 1-й -- самый явный emp.join(dept, emp.dept_id == dept.dept_id, "inner") emp.join(dept, emp.dept_id == dept.dept_id) emp.join(dept, "dept_id") """ +-------+------+---------+------+---------+ |dept_id|emp_id| emp_name|salary|dept_name| +-------+------+---------+------+---------+ | 1| 2| Roman| 4500| IT| | 1| 3| Tom| 5500| IT| | 1| 9| Felix| 5500| IT| | 3| 4| Alex| 3000| HR| | 3| 12| Tom| 3500| HR| | 3| 16| Polly| 3800| HR| | 2| 1|Alexander| 3500| Admin| | 2| 7| Svetlana| 3000| Admin| | 2| 14| John| 3500| Admin| | 4| 5| Arthur| 4250| Finance| | 4| 6| Anna| 3520| Finance| | 4| 11| Anna| 6320| Finance| | 4| 13| Felix| 3520| Finance| +-------+------+---------+------+---------+ """
Как видим, три сотрудника из 5-го неизвестного отдела не были включены в результирующую таблицу.
LEFT JOIN в PySpark
При использовании LEFT JOIN выбираются записи, которые соответствуют второй таблице. Если совпадений нет, то возвращается null. Иными словами, таблица слева будет все записи.
Пример кода PySpark, который демонстрирует работу LEFT JOIN:
emp.join(dept, "dept_id", "left") """ +-------+------+---------+------+---------+ |dept_id|emp_id| emp_name|salary|dept_name| +-------+------+---------+------+---------+ | 5| 8| Oleg| 3200| null| | 5| 10| Olga| 4970| null| | 5| 15| Finn| 5570| null| | 1| 2| Roman| 4500| IT| | 1| 3| Tom| 5500| IT| | 1| 9| Felix| 5500| IT| | 3| 4| Alex| 3000| HR| | 3| 12| Tom| 3500| HR| | 3| 16| Polly| 3800| HR| | 2| 1|Alexander| 3500| Admin| | 2| 7| Svetlana| 3000| Admin| | 2| 14| John| 3500| Admin| | 4| 5| Arthur| 4250| Finance| | 4| 6| Anna| 3520| Finance| | 4| 11| Anna| 6320| Finance| | 4| 13| Felix| 3520| Finance| +-------+------+---------+------+---------+ """
Мы можем выбрать только нужные нам столбцы:
emp.join(dept, emp.dept_id == dept.dept_id, "left") \
.select("emp_name", "dept_name")
"""
+---------+---------+
| emp_name|dept_name|
+---------+---------+
| Oleg| null|
| Olga| null|
| Finn| null|
| Roman| IT|
| Tom| IT|
| Felix| IT|
| Alex| HR|
| Tom| HR|
| Polly| HR|
|Alexander| Admin|
| Svetlana| Admin|
| John| Admin|
| Arthur| Finance|
| Anna| Finance|
| Anna| Finance|
| Felix| Finance|
+---------+---------+
"""
Левое соединение можно рассматривать как: INNER JOIN + записи из левой таблицы.
RIGHT JOIN в PySpark
Следующий тип соединения — RIGHT JOIN. Очевидно, что он противоположный левому соединению. Правое соединение выбирает записи, которые совпадают с первой таблицей.
Пример RIGHT JOIN в PySpark:
emp.join(dept, emp.dept_id == dept.dept_id, "left") """ +------+---------+-------+------+-------+---------+ |emp_id| emp_name|dept_id|salary|dept_id|dept_name| +------+---------+-------+------+-------+---------+ | null| null| null| null| 6|Marketing| | 2| Roman| 1| 4500| 1| IT| | 3| Tom| 1| 5500| 1| IT| | 9| Felix| 1| 5500| 1| IT| | 4| Alex| 3| 3000| 3| HR| | 12| Tom| 3| 3500| 3| HR| | 16| Polly| 3| 3800| 3| HR| | 1|Alexander| 2| 3500| 2| Admin| | 7| Svetlana| 2| 3000| 2| Admin| | 14| John| 2| 3500| 2| Admin| | 5| Arthur| 4| 4250| 4| Finance| | 6| Anna| 4| 3520| 4| Finance| | 11| Anna| 4| 6320| 4| Finance| | 13| Felix| 4| 3520| 4| Finance| +------+---------+-------+------+-------+---------+ """
Здесь мы видим, что к отделу маркетинга никто не относится, поэтому он заполняется null-ами.
Если мы поменяем местами таблицы и используем левое соединение, то получим тот же результат:
dept.join(emp, "dept_id", "left")
FULL JOIN
FULL JOIN — это комбинация из левого и правого соединения. Иными словами, выдаст null для недостающих записей слева и справа.
Пример RIGHT JOIN в PySpark:
emp.join(dept, "dept_id", "full") """ +-------+------+---------+------+---------+ |dept_id|emp_id| emp_name|salary|dept_name| +-------+------+---------+------+---------+ | 6| null| null| null|Marketing| | 5| 8| Oleg| 3200| null| | 5| 10| Olga| 4970| null| | 5| 15| Finn| 5570| null| | 1| 2| Roman| 4500| IT| | 1| 3| Tom| 5500| IT| | 1| 9| Felix| 5500| IT| | 3| 4| Alex| 3000| HR| | 3| 12| Tom| 3500| HR| | 3| 16| Polly| 3800| HR| | 2| 1|Alexander| 3500| Admin| | 2| 7| Svetlana| 3000| Admin| | 2| 14| John| 3500| Admin| | 4| 5| Arthur| 4250| Finance| | 4| 6| Anna| 3520| Finance| | 4| 11| Anna| 6320| Finance| | 4| 13| Felix| 3520| Finance| +-------+------+---------+------+---------+ """
Помимо классических PySpark поддерживает еще разные типы соединений, с которыми можете ознакомиться в документации [1]. Также отметим, что результат операции соединения легко понять, однако то, что стоит “под капотом” уже другое дело. Если вы применяли соединения в своих запросов, то заметили, что даже для маленьких таблиц она выполняется не быстро. Это связано с перетасовкой (shuffle). Дело в том, что в одном исполнителе могут не оказаться совпадающих записей, поэтому запуститься перетасовка. Последующая операция преобразования также потребует совершить эту перетасовку. В этом случае мы можем разве что уменьшить их количество. Как это сделать рассказывали в отдельной статье, также используйте бакетирование.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
6 апреля, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200 руб.
А о том, как использовать соединение таблиц наиболее оптимальным способом вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и IT-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков

