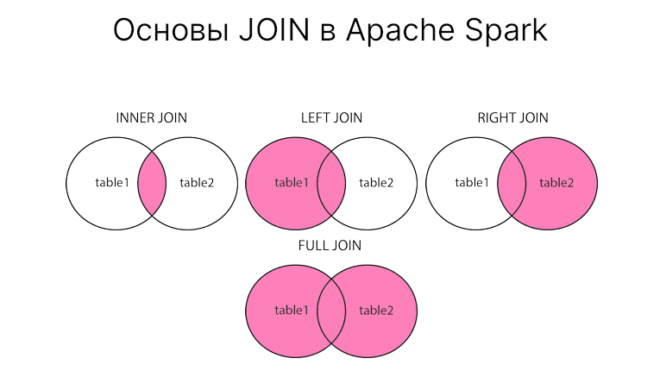
Иногда приходится работать с несколькими связанными таблицами сразу, причем требуется их каким-то образом соединять. В этом случае вам поможет операция JOIN в PySpark. Сегодня расскажем...
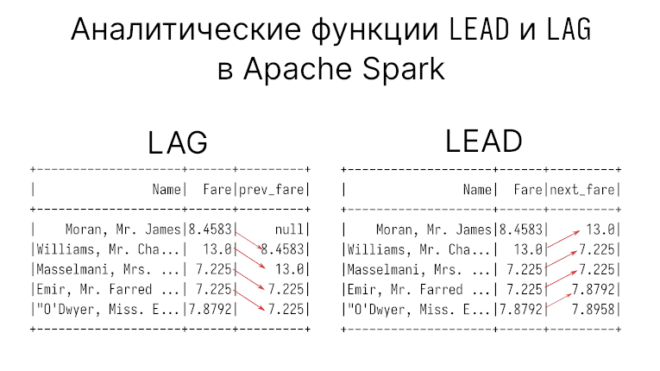
Оконные функции: LAG и LEAD
В предыдущей статье мы говорили о ранжирующих функциях из семейство оконных (window function) в PySpark. В этой статье пойдет речь об аналитических функциях LEAD и...
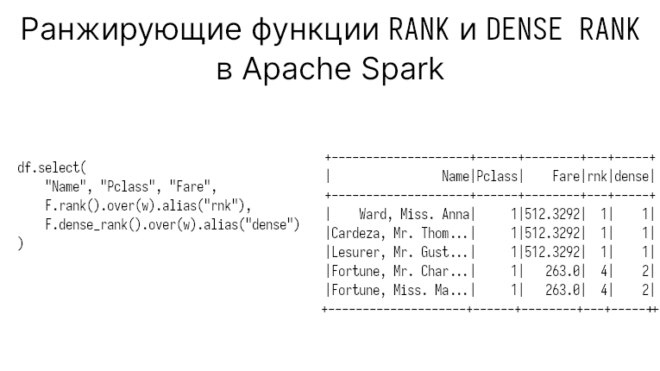
Зачем вам вычислять ранг RANK и DENSE RANK
В прошлой статье мы говорили о ранжирующей функции ROWS NUMBER в PySpark. Сегодня поговорим о RANK DENSE_RANK, а также узнаем, чем они различаются. Данные с...

Зачем вам считать строки ROW NUMBER
В прошлый раз мы говорили о использовании агрегирующих функциях с использованием окон (window function) в PySpark. Сегодня поговорим об одной из ранжирующих функций ROW NUMBER,...
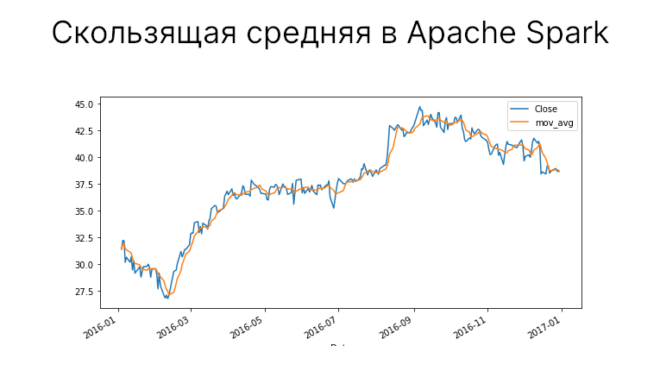
Как посчитать скользящую среднюю
Скользящая средняя (moving average) часто применяется для анализа и определения трендов в данных. Она рассчитывается как среднее текущего и заданного числа предыдущих значений за некоторый...
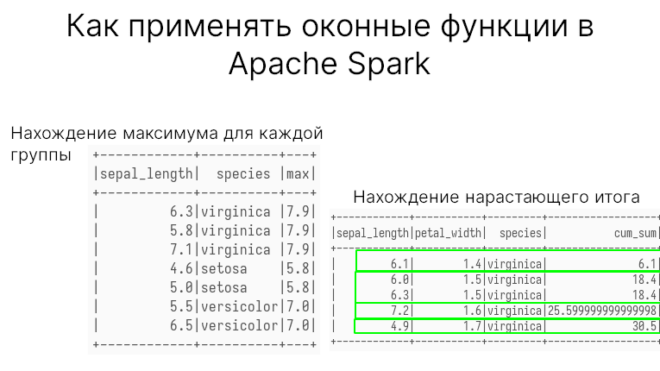
Зачем вам оконные функции в Apache Spark
Apache Spark SQL поддерживает оконные функции (window functions), которые могут пригодиться для различных задач, например для получения нарастающего значения или скользящей средней. В этой статье...

Оконные функции: NTH, NTILE, CUME_DIST, PERCENT_RANK
В предыдущей статье мы говорили о фреймах оконных функций (window functions) в PySpark. Сегодня мы затронем такие аналитические функции, как NTH, NTILE, CUME_DIST, PERCENT_RANK. Исходные...
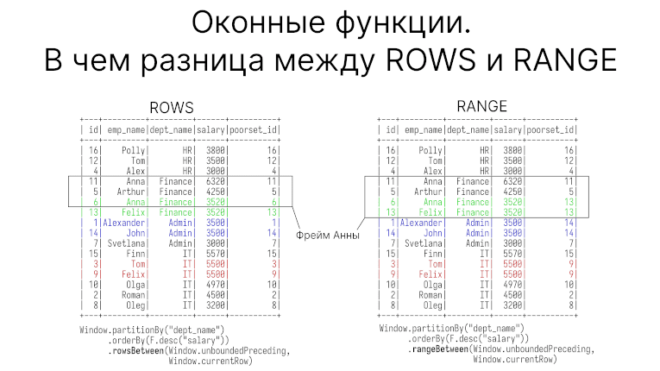
Как задаются границы фрейма в оконных функциях
Оконные функции (window functions) — один из полезных инструментов для обработки и анализа данных в PySpark. В этой статье на примере простых функций first_value и...
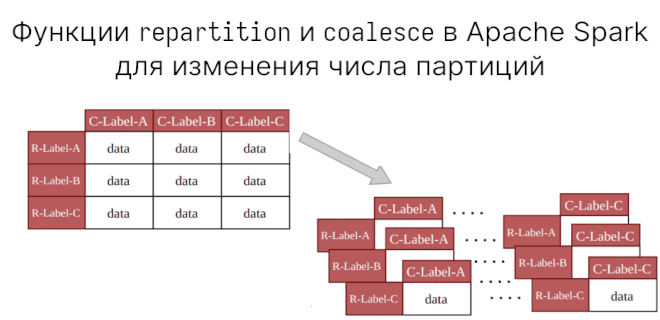
Зачем вам функции repartition и coalesce
Мы уже говорили о создании партиций (partitions) на диске с помощью partitionBy. В Apache Spark есть еще функции для работы с партициями. Сегодня рассмотрим разницу...

4 совета по оптимизации Apache Spark
В прошлый раз мы рассмотрели 6 способов повышения производительности Apache Spark: кэширование, трансляция, бакетирование, минимизация перетасовки (shuffle), применение оконных функций и контрольных точек. Дадим еще...