
Apache Maven — это фреймворк для автоматической сборки проектов на основе описания их структуры в специальных файлах на языке POM (Project Object Model). POM-файл представляет собой структурированный (упорядоченный) набор параметров для сборки проекта (например, версия проекта и зависимости) на языке XML (Extensible Markup Language) [1].

Что такое Maven: основные особенности архитектуры
Мавен — это инструмент управления сборкой проектов, который базируется на плагиновой архитектуре (plugin architecture), позволяющей применять плагины для различных задач (например, компиляция, сборка, развертывание). Плагин — это независимый программный модуль, который подключается к основной программе (или проекту) для расширения ее возможностей (функционала).
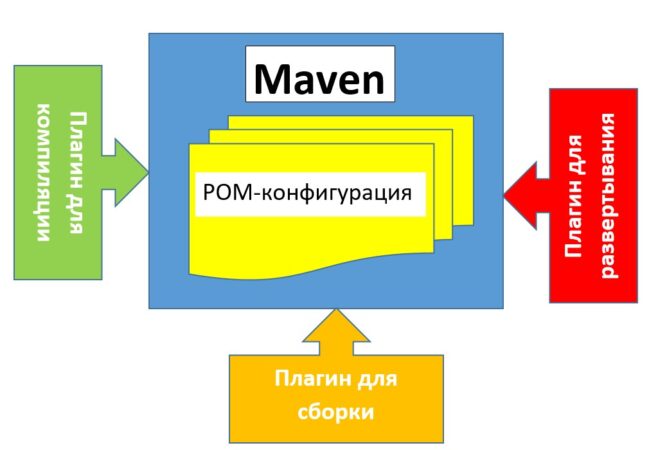
Структура Мавен-проекта задается в POM-файле и включает в себя следующие элементы:
- Репозитории — это специальные хранилища для сторонних (подгружаемых извне) библиотек. При сборке проекта Мавен ищет необходимые файлы библиоткек в локальном maven-репозитории. Если этот репозиторий не содержит указанной библиотеки, Мавен подключается к указанному maven-репозиторию в сети и копирует необходимые файлы в локальный репозиторий для возможности повторного использования при сборке нового проекта.
- Зависимости — это элементы, используемые для автоматической подгрузки необходимых библиотек из репозиториев. Зависимости также позволяют контролировать версии подгружаемых библиотек (например, можно подгрузить более новую или более старую версию).
- Менеджеры репозиториев — репозитории реализуется с помощью специальных менеджеров репозиториев Мавен (Maven Repository Manager), таких как Apache Archiva, Nexus, Artifactory, Codehaus Maven Proxy или Simple Maven Proxy. Менеджеры репозиториев отвечают за построение структуры и ее управление (например, добавление папок в корневой каталог, а также распределение файлов по этим папкам) [1].
Как появился Мавен: краткая история
Разработка Мавен началась в 2002 году канадским разработчиком Ясоном ван Зилом. В 2003 году появилась первая версия Maven 1.x, которая была опубликована 13 июля 2004 года как версия 1.0. Однако в этой версии Мавен были большие проблемы с производительностью из-за слишком большой конфигурации. С целью устранить этот недостаток началась разработка Мавен 2.x в 2005 году, которая впервые была опубликована как Мавен 2.0 19 октября 2005 года. В 2008 году началась масштабная разработка третьей версии Мавен 3.x для возможности поддержки плагинов. После восьми альфа-релизов, в октябре 2010 года была опубликована версия Maven 3.0. Была также добавлена возможность совместимости Maven 3.0 с Maven 2. Последняя версия Maven 3.6.3 была опубликована 25 ноября 2019 года [1].
Сборка Spark-приложений с Maven
Одна из главных причин сборки Spark-приложений с помощью Мавен — это простота настройки: для добавления нового функционала в проект нужно всего лишь добавить новую зависимость для подгрузки необходимой библиотеки. Как уже упоминалось выше, зависимости являются частью конфигурации, описанной в POM-файле. Зависимости указываются в блоке <dependencies> </dependencies>. Каждая отдельная зависимость (для подгрузки новой библиотеки) выносится в отдельный подблок <dependency> </dependency>. Следующий код на языке XML отвечает за определение зависимостей для подгрузки библиотек, использующихся в приложении на базе фреймворка Spark [2]:
<!-- Блок зависимостей --> <dependencies> <!-- Зависимость Spark --> <dependency> <groupid>org.apache.spark</groupid> <artifactid>spark-core_2.10</artifactid> <version>l.2.0</version> <scope>provided</scope> </dependency> <!-- Сторонняя библиотека --> <dependency> <groupid>net.sf.jopt-simple</groupid> <artifactid>jopt-simple</artifactid> <version>4.3</version> </dependency> <!-- Сторонняя библиотека --> <dependency> <groupid>joda-time</groupid> <artifactid>joda-time</artifactid> <version>2.0</version> </dependency> </dependencies>
Таким образом, благодаря автоматическому сборщику приложений Мавен, Spark-приложения могут легко компилироваться и развертываться в распределенной среде (на сервере приложений), освобождая разработчика от необходимости длительных «ручных» настроек. Это делает Maven неотъемлемой частью технологий работы с большими данными, включая Apache Spark, Kafka и другие технологии Big Data.
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники
- https://ru.wikipedia.org/wiki/Apache_Maven
- К.Харау, Э.Ковински, П.Венделл, М.Захария. Изучаем Spark: молниеносный анализ данных