
В прошлой статье мы говорили про общие переменные в Apache Spark. Сегодня рассмотрим пользовательские функции и их применение в Spark. Читайте далее про особенности создания и применения UDF для работы с Big Data во фреймворке Apache Spark.
Что такое пользовательские функции в Spark: особенности создания и применения
Пользовательские функции (User Defined Functions, UDF) — это функции, которые не являются встроенными (уже имеющимися) и создаются самим пользователем во время работы с данными при необходимости получить желаемый результат. UDF-функции обычно создаются для дополнительной обработки и могут содержать в себе несколько встроенных функций одновременно. Например, следующий код отвечает за определение функции, которая возводит все указанные числа в квадрат и возвращает результат в виде списка:
def square_array_right(x): return np.square(x).tolist()
Как видно из кода, при возвращении нужного результата пользовательская функция использует встроенные функции np.square() (функция библиотеки numpy для возведения указанного числа в квадрат) и tolist() (функция для формирования списка из указанных элементов) [1].
Работа с пользовательскими функциями в Spark: несколько практических примеров
Для того, чтобы создать пользовательскую функцию, ее необходимо сначала определить. Это можно сделать с помощью ключевого слова def. Следующий код на языке Python отвечает за определение пользовательской функции для подсчета квадратов чисел:
def square(x): return x**2
Для корректной работы с данными в Spark необходимо указывать тип выходных данных. Для этого необходимо зарегистрировать UDF-функцию с помощью метода udf() и указать в качестве параметров регистрируемую функцию и тип выходных данных:
from pyspark.sql.types import IntegerType square_udf_int = udf(lambda z: square(z), IntegerType())
Созданную пользовательскую функцию можно использовать для того, чтобы получить квадраты всех чисел в датафрейме. Следующий код на языке Python отвечает за создание числового датафрейма и возведение всех его чисел в квадрат:
df_pd = pd.DataFrame(
data={'integers': [1, 2, 3],
'floats': [-1.0, 0.5, 2.7],
'integer_arrays': [[1, 2], [3, 4, 5], [6, 7, 8, 9]]})
df = spark.createDataFrame(df_pd)
df.select('integers','floats',
square_udf_int('integers').alias('int_squared'),
square_udf_int('floats').alias('float_squared')).show()

Из результата видно, что при возведении чисел с плавающей точкой возникла проблема в виде null-результата. Это произошло по причине того, что при создании UDF-функции был указан целый (Integer) тип получаемого результата. Для того, чтобы это исправить, необходимо изменить целый тип возвращаемого результата на тип с плавающей точкой (float):
from pyspark.sql.types import FloatType
square_udf_float = udf(lambda z: square(z), FloatType())
df.select('integers',
'floats',square_udf_float('integers').alias('int_squared'),
square_udf_float('floats').alias('float_squared')).show()
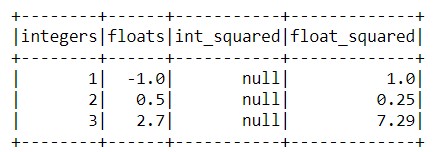
Теперь возникла проблема в виде null-значений при возведении в квадрат целых чисел. Чтобы избежать этого, необходимо привести возвращаемый результат к типу Float при определении функции следующим образом:
def square(x): return float(x**2)
Теперь можно без проблем возводить в квадрат числа типов Integer и Float [2]:
square_udf_float = udf(lambda z: square_float(z), FloatType())

Можно заметить, что результат возведения в квадрат целых и дробных чисел имеет тип Float. Такой подход отлично решает проблему с конфликтом типов данных и исключает возможность получения некорректного результата.
Таким образом, благодаря поддержке пользовательских функций, фреймворк Apache Spark позволяет пользователям работать с большими данными, не ограничивая их в методике обработки. Все это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы поговорим про сборку Spark-приложений.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники

