
Построение моделей машинного обучения в Spark — это последовательный процесс. Сегодня мы расскажем о конвейерах (Pipeline) в Spark. Читайте далее: какие объекты используются в конвейере, как он работает, что такое Transfrormer и Estmator, а также как передаются параметры в модели Machine learning.
Структура MLlib
MLlib стандартизирует API-интерфейсы для алгоритмов машинного обучения, чтобы упростить объединение нескольких алгоритмов в один конвейер или рабочий процесс. Концепция конвейера в основном вдохновлена проектом Scikit-learn — библиотекой Python. В Spark-модулей MLlib имеется такие основные объекты как:
- DataFrame — это тот же DataFrame из Spark SQL, он может содержать различные типы данных. Например, DataFrame может иметь разные столбцы с текстом, векторами, метками и прогнозами.
- Transformer (преобразователь) преобразует один DataFrame в другой. Например, модель машинного обучения в Spark преобразует исходный набор данных в DataFrame с прогнозами.
- Estimator — это алгоритм, который применяется над DataFrame для создания преобразователя (Transformer). Например, для алгоритмов машинного обучения — это сам процесс обучения (в зависимости от алгоритма он свой).
- Pipeline — конвейер, который связывает несколько Transformer и Estimator вместе для объединения рабочего процесса машинного обучения.
- Parameter используетсяя для определения параметров.
Transformer (Преобразователь)
Transformer служит для преобразования признаков и обученных моделей. Технически Transformer реализует метод transform, который преобразует один DataFrame в другой, обычно путем добавления одного или нескольких столбцов. Например:
- Для преобразования признаков Spark читает указанный столбец, преобразует его в новый столбец и возвращает новый DataFrame с дополненным столбцом. Примером может служить VectorAssembler, который преобразует столбцы в векторы (о нем мы говорили тут).
- Для обучения модели Spark читает указанный столбец с векторами, предсказывает значения, исходя из алгоритма Machine Learning, и возвращает новый DataFrame с дополненным столбцов прогнозов.
Estimator
Estimator абстрагирует концепцию алгоритма обучения. Технически Estimator реализует метод fit, который принимает DataFrame и создает модель, которая является преобразователем. Любой алгоритм обучения, например, логистическая регрессия, является Estimator, а вызов fit проводит процесс обучения и возвращает LogisticRegressionModel, которая является моделью и, следовательно, преобразователем (Transformer).
Pipeline (конвейер) — это объединение Transformer и Estimator
В машинном обучении принято запускать последовательность некотрых алгоритмов для обработки данных и обучения на их основе. Например, простой рабочий процесс обработки текстового документа может включать в себя несколько этапов:
- Разделение текста каждого документа на слова, этот процесс называется токенизацией.
- Преобразование слов каждого документа в числовой вектор признаков.
- Обучение на основе полученных признаков модели.
Модуль MLlib представляет такой рабочий процесс как конвейер, который состоит из последовательности Transformers и Estimators, которые должны выполняться в определенном порядке.
Итак, внутри конвейера данным исходного датафрейма то преобразуется (transform), то обучается (fit). Причем метод fit возвращает преобразователь, а transform — новый датафейм.
Как работает Pipeline
Проиллюстрируем это на примере NLP задачи. Допустим, нужно сначала текст разбить на токены, затем представить в числовом виде, например, с помощью подсчета частоты слова (с помощью HashingTF), а после передать полученный столбец логистической регрессии. Возвращаемый объект Pipeline будет зависеть от того, какой метод вы вызываете — fit или transfrom.
При вызове метода fit конвейер в свою очередь вызовет методы transform объектов Tokenizer и HashingTF, поскольку у них нет метода fit. Но вот логистическая регрессия в Spark имеет метод fit, поэтому вернется LogisticRegressionModel, с помощью которой можно получать прогнозы с тестовой выборки.
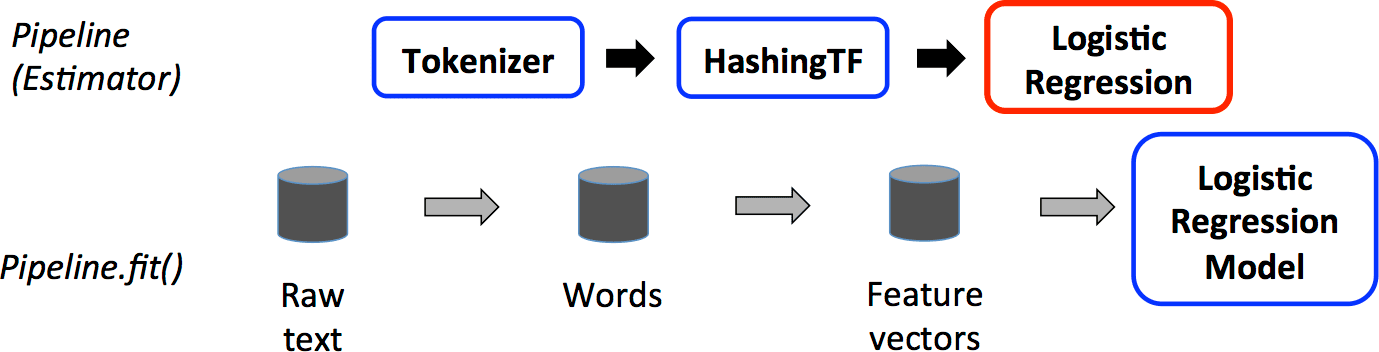
При вызове метода transform результатом будет являться объект DataFrame с прогнозами на основе переданных данных. Все промежуточные результаты преобразований сохраняются.
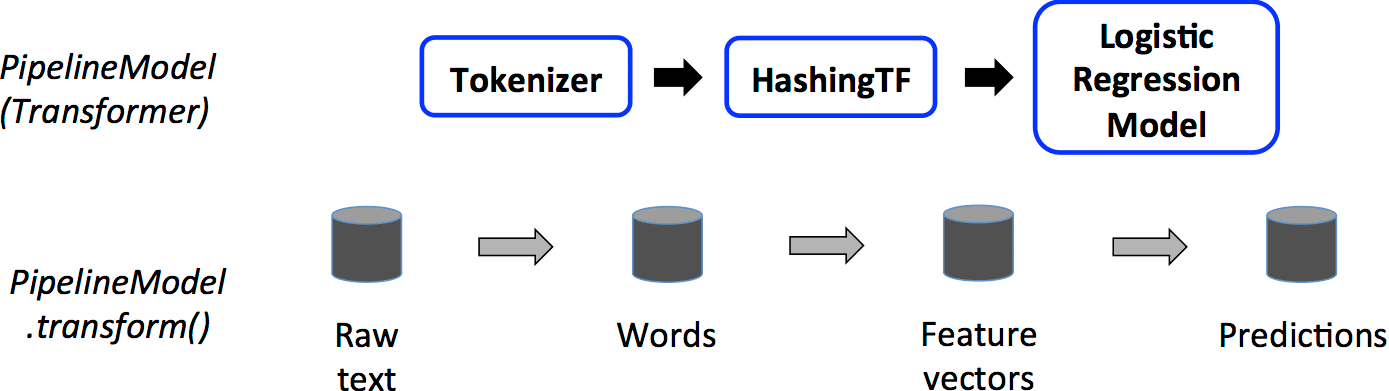
Для алгоритмов машинного обучения в Spark метод fit необходим для обучения модели, а transfrom — для тестирования и предсказаний.
Параметры
В Spark-модуле MLlib есть еще один объект — Paramater (параметр). Estimator и Transformer используют один API для своих параметров. Param — это именованный параметр с своей документацией. ParamMap — это набор пар (параметр, значение).
Есть два основных способа передать параметры алгоритму:
- Вызывать соответствующие атрибуты. Например, если объект LogisticRegression может вызвать
lr.setMaxIter(10), чтобы при обучении использовать не более 10 итераций. - Передать ParamMap в
fitилиtransform. Любые параметры в ParamMap переопределят ранее указанные.
Пример использования Pipeline
Построим конвейер в Spark для классификации текстовых документов. Так, для токенизации нужен класс Tokenizer, для подсчета частоты токенов — объект HashingTF, а для классификации воспользуемся логистической регрессией. Все эти объекты нужно передать конвейеру через параметр stages в том порядке, в котором мы хотим произвести обработку.
Пример кода с обучением модели через метод fit в Spark выглядит следующим образом:
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF, Tokenizer
training = spark.createDataFrame([
(0, "a b c d e spark", 1.0),
(1, "b d", 0.0),
(2, "spark f g h", 1.0),
(3, "hadoop mapreduce", 0.0)
], ["id", "text", "label"])
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.001)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(training)
А вот для получения предсказаний используется метод transform. Пример датафрейма с предсказанными значениями в Spark:
test = spark.createDataFrame([
(4, "spark i j k"),
(5, "l m n"),
(6, "spark hadoop spark"),
(7, "apache hadoop")
], ["id", "text"])
prediction = model.transform(test)
prediction.show()
+---+------------------+--------------------+----------+ | id| text| probability|prediction| +---+------------------+--------------------+----------+ | 4| spark i j k|[0.15964077387874...| 1.0| | 5| l m n|[0.83783256854767...| 0.0| | 6|spark hadoop spark|[0.06926633132976...| 1.0| | 7| apache hadoop|[0.98215753334442...| 0.0| +---+------------------+--------------------+----------+
Еще больше подробностей о машинном обучении и конвейерах в Spark вы узнаете на специализированном курсе «Машинное обучение в Apache Spark» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

