
В прошлой статье мы говорили о преимуществах Spark NLP. Сегодня рассмотрим, как установить Spark NLP и PySpark в Windows, Linux (Ubuntu) и Google Colab. В этой статье мы шаг за шагом разберем ход установки не только самой библиотеки, но и самого фреймворка Apache Spark на разных операционных системах.
Установка Spark NLP на Windows
Установка Apache Spark и Spark NLP в Windows потребует немного времени и сил, что не скажешь о Unix-системах. Нужно будет скачать соответствующие программы и установить переменные окружения.
Установка Apache Spark и Java
Если у вас не стоит Java 8, то скачиваете и устанавливаете OpenJDK 64-bit отсюда. При установке убедитесь, что переменная среды JAVA_HOME задана. В любом случае нужно будет проверить все переменные среды, если их не будет, то зададим вручную.
Скачайте winutils отсюда и положите файл в директорию C:\hadoop\bin. Если такой директории нет, то создайте.
Скачайте Apache Spark 2.4.7 отсюда и извлеките в директорию C так, что получится C:\spark-2.4.7-bin-hadoop2.7.
Также может понадобится пакет vcredist_x64.exe со страницы Microsoft. Его нужно просто установить.
Определение переменных окружения
Переменные среды (environment variable) нужны для того, чтобы вы в командной строке могли запускать программы. Если вы можете запустить, например, Python в командной строке, значит в переменной среды PATH задан путь до выполняемой программы Python.
Чтобы установить переменные окружения можете использовать Поиск и ввести “переменные среды” (если система на английском, то “environment variables”). Там вам нужно будет добавить системные переменные среды.
Нужно установить две системные переменные HADOOP_HOME и SPARK_HOME, которые равны соответственно C:\hadoop и C:\spark-2.4.7-bin-hadoop2.7 (см. рисунок ниже).
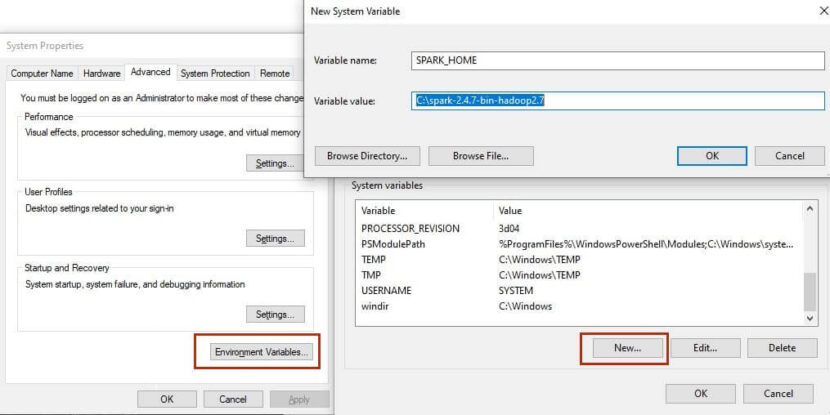
После этого нужно добавить пути до самих программ. Для этого в списке системных переменных найдите PATH, нажмите редактировать и добавьте %HADOOP_HOME%\bin и %SPARK_HOME%\bin, как это показано на рисунке ниже.
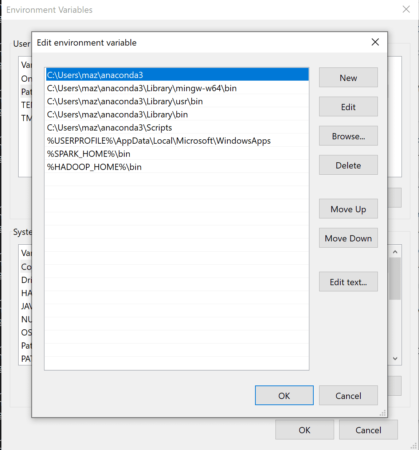
Также убедитесь, что у вас есть переменная JAVA_HOME и в пути стоит %JAVA_HOME%\bin. Если нет, то сделайте это вручную. По умолчанию после установки директория Java обычно находится в Program Files, поэтому переменная будет C:\Program Files\java.
Также нужно создать директории C:\temp и C:\temp\hive. Затем в командной строке вводите следующее (это разрешение на использование директории для всех пользователей):
%HADOOP_HOME%\bin\winutils.exe chmod 777 /tmp/ %HADOOP_HOME%\bin\winutils.exe chmod 777 /tmp/hive
Проверка работы установленных программ
Чтобы убедиться что все работает в командной строке можете ввести следующие команды:
java -version pyspark --version
Каждая из них выдаст свою версию. Нечто подобное для Java:
openjdk version "16" 2021-03-16 OpenJDK Runtime Environment (build 16+36-2231) OpenJDK 64-Bit Server VM (build 16+36-2231, mixed mode, sharing)
И для PySpark:
version 2.4.7 Using Scala version 2.11.12, OpenJDK Client VM, 1.8.0_41
Осталось только установить Spark NLP.
Установка Spark NLP
В той же командной строке установите Spark NLP, findspark и numpy (если его нет). Тут уже в зависимости каким пакетным менеджером вы пользуетесь: conda или pip. Через Pip установка Spark NLP выглядит слеующим образом:
pip install spark-nlp==2.7.5 findspark numpy
для Anaconda или Miniconda две команды:
conda install -c johnsnowlabs spark-nlp conda install -c conda-forge findspark numpy
Пакет findspark найдет Spark на компьютере, иначе бы мы не смоги импортировать pyspark.
На этом все. Можете запустить Python и проверить работоспособность установленных библиотек:
import findspark findsaprk.init() import sparknlp spark = sparknlp.start()
Установка Spark NLP на Ubuntu Linux
OpenJDK 8 есть в стандартных пакетах многих дистрибутивов, включая Ubuntu, Debian и Arch. А вот Spark придется качать вручную (можно через wget или curl). Иными словами, установить все необходимое можно, не выходя из эмулятора терминала.
Следующие команды установят OpenJDK, скачают архив Spark, разорхивирует его в созданной папке spark:
apt-get install -y openjdk-8-jdk-headless mkdir spark cd spark wget https://www.apache.org/dyn/closer.lua/spark/spark-2.4.7/spark-2.4.7-bin-hadoop2.7.tgz tar -xzvf spark-2.4.7-bin-hadoop2.7.tgz
Через команндую строку можем добавить переменные среды. Запишем их в файл .profile (можно также использовать .bashrc):
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> ~/.profile echo "export PATH=$PATH:$JAVA_HOME/bin" >> ~/.profile echo "export SPARK_HOME=~/spark" >> ~/.profile echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.profile echo "export PYSPARK_PYTHON=python3" >> ~/.profile echo "export PYSPARK_DRIVER_PYTHON=jupyter" >> ~/.profile echo "export PYSPARK_DRIVER_PYTHON_OPTS=notebook" >> ~/.profile
Установка пакетов Spark NLP осуществляется также, как это указано выше.
Ленивый способ — Google Colab
Если вы не хотите ничего устанавливать у себя на компьютере, то вы можете воспользоваться Google Colab. Там тоже стоит Ubuntu, но все делается гораздо проще.
В свою первую ячейку Google Colab скопируйте следующие строки:
!apt-get install -y openjdk-8-jdk-headless -qq > /dev/null !pip install -q pyspark==2.4.7 !pip install -q spark-nlp==2.7.5 import os os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" os.environ["PATH"] = os.environ["JAVA_HOME"] + "/bin:" + os.environ["PATH"]
И все. Можете работать с PySpark и Spark NLP, тренировать модели, эксплуатировать GPU. О том, что такое Google Colab и как в нем работать смотрите видеоролик ниже.
Еще больше подробностей о работе в Apache Spark с обучением на реальных примерах Data Science вы узнаете на специализированном курсе «Основы Apache Spark для разработчиков» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

