
Подготовка датасетов в PySpark — одна из задач, которую необходимо выполнить для последующего анализа данных или обучения моделей Machine Learning. Сегодня мы поговорим о работе с векторами. Читайте в этой статье: как преобразовать столбцы в векторы, привести признаки к категориям, разрезать векторы с указанными индексами, а также как провести поэлементное умножение векторов в PySpark.
VectorAssembler: преобразование столбцов в векторы в PySpark
VectorAssembler объединяет заданный список столбцов в один векторный столбец. Является, пожалуй, самым важным векторным преобразователем в PySpark, поскольку модели машинного обучения требуют на вход векторы. VectorAssembler принимает следующие типы входных столбцов: числовые, логические и векторные. Не принимает столбцы со строками. Значения входных столбцов будут объединены в вектор в указанном порядке. В аргументе inputCols указываются столбцы, которые нужно преобразовать, а outputCol — это название выходного столбца (по умолчанию features). Пример преобразования в векторы в PySpark:
from pyspark.ml.linalg import Vectors
from pyspark.ml.feature import VectorAssembler
dataset = spark.createDataFrame(
schema=["id", "hour", "mobile", "userFeatures", "clicked"],
data=[
(0, 18, True, Vectors.dense([0.0, 10.0, 0.5]), 1.0),
(1, 12, False, Vectors.dense([1.0, 18.0, 1.5]), 0.0)
])
assembler = VectorAssembler(
inputCols=["hour", "mobile", "userFeatures"],
outputCol="features")
print('До:')
dataset.show()
print('После (обратите внимание на True и False):')
output = assembler.transform(dataset)
output.select("features", "clicked").show(truncate=False)
До: +---+----+------+--------------+-------+ | id|hour|mobile| userFeatures|clicked| +---+----+------+--------------+-------+ | 0| 18| true|[0.0,10.0,0.5]| 1.0| | 1| 12| false|[1.0,18.0,1.5]| 0.0| +---+----+------+--------------+-------+ После (обратите внимание на True и False): +-----------------------+-------+ |features |clicked| +-----------------------+-------+ |[18.0,1.0,0.0,10.0,0.5]|1.0 | |[12.0,0.0,1.0,18.0,1.5]|0.0 | +-----------------------+-------+
VectorIndexer: индексирование категорий
VectorIndexer помогает индексировать категориальные векторные признаки. Этот класс сам определяет, какие признаки в векторе являются категориальными и преобразует их в индексы категорий. В частности, VectorIndexer производит следующее:
- Принимает на вход столбец с вектором, а также параметр
maxCategories. - Решает, какие признаки должны быть категориальными, опираясь на количество уникальных значений отдельного признака. Так, те признаки, у которых количество уникальных значений меньше, чем
maxCategories, будут объявлены категориальными. - Вычисляет индексы категорий, начиная индексацию с нуля.
- Индексирует категориальные признаки и преобразует исходные значения признаков в индексы (категории).
Индексирование категориальных признаков позволяет таким алгоритмам, как Decision Trees (деревья решения) и Tree Ensembles (Ансамбли деревьев), соответствующим образом обрабатывать эти признаки.
Прочитаем результат VectorAssembler (тот, что выше), а затем применим над ним VectorIndexer, чтобы решить, какие признаки следует рассматривать как категориальные. Эти преобразованные векторы затем могут быть переданы в один из алгоритмов PySpark, например DecisionTreeRegressor.
from pyspark.ml.feature import VectorIndexer
indexer = VectorIndexer(inputCol="features", outputCol="indexed",
maxCategories=2)
indexerModel = indexer.fit(output)
categoricalFeatures = indexerModel.categoryMaps
print("Всего нашлось %d категориальных признаков" %
(len(categoricalFeatures)))
# output из примера выше (VectorAssembler)
indexedData = indexerModel.transform(output)
indexedData.select('features', 'indexed').show(truncate=False)
Всего нашлось 5 категориальных признаков +-----------------------+---------------------+ |features |indexed | +-----------------------+---------------------+ |[18.0,1.0,0.0,10.0,0.5]|[1.0,1.0,0.0,0.0,0.0]| |[12.0,0.0,1.0,18.0,1.5]|[0.0,0.0,1.0,1.0,1.0]| +-----------------------+---------------------+
VectorSlicer: разрезаем векторы
VectorSlicer принимает на вход вектор признаков и выводит новый вектор с подмассивом исходных признаков. Иными словами, это то же самое разрезание списков в Python, например, list[5:10] — взять все элементы, начиная с 5-го индекса и заканчивая 10-м.
VectorSlicer в PySpark выводит новые вектора, основываясь на следующих двух типах индексов:
- Целочисленные индексы, представляющие индексы в векторе. За это отвечает параметр
indices. - Строковые индексы, представляющие названия признаков. Указывается в параметре
names.
Должен быть указан хотя бы один из этих параметров. Ниже пример в PySpark для разрезания вектора. Диапазон индексов указан в параметре indices.
from pyspark.ml.feature import VectorSlicer
from pyspark.ml.linalg import Vectors
df = spark.createDataFrame(
schema=['userFeatures'],
data=[
[Vectors.dense([3.0, -2.0, 2.3, 4.7])],
[Vectors.dense([-2.0, 2.3, 0.0, 5.4])]
])
slicer = VectorSlicer(inputCol="userFeatures", outputCol="features",
indices=[1, 2])
output = slicer.transform(df)
output.select("userFeatures", "features").show()
+------------------+----------+ | userFeatures| features| +------------------+----------+ |[3.0,-2.0,2.3,4.7]|[-2.0,2.3]| |[-2.0,2.3,0.0,5.4]| [2.3,0.0]| +------------------+----------+
ElementwiseProduct: поэлементное умножение
Поэлементное умножение между двумя векторами в PySpark осуществляется через ElementwiseProduct. Умножаются только те элементы, которые имеют одинаковые индексы.
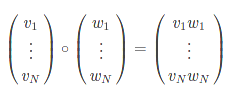
В аргументе scalingVec указывается, на какой вектор нужно умножить выбранный столбец. Пример в PySpark для поэлементного умножения векторов:
from pyspark.ml.feature import ElementwiseProduct
df = spark.createDataFrame(
data=[
[Vectors.dense([1.0, 2.0, 3.0]),],
[Vectors.dense([4.0, 5.0, 6.0]),]
], schema=["vector"])
transformer = ElementwiseProduct(
scalingVec=[0.0, 1.0, 2.0],
inputCol="vector", outputCol="transformedVector")
transformer.transform(df).show()
+-------------+-----------------+ | vector|transformedVector| +-------------+-----------------+ |[1.0,2.0,3.0]| [0.0,2.0,6.0]| |[4.0,5.0,6.0]| [0.0,5.0,12.0]| +-------------+-----------------+
О том, как работать с векторами Spark и подготавливать датасеты для решения реальных задач Machine Learning, вы узнаете на специализированном курсе «Машинное обучение в Apache Spark» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

