
Apache Spark применяется для работы с большими данными (Big Data), поэтому встает вопрос: как увеличить скорости обработки этих данных. В этой статье мы рассмотрим 5 способов, которые могут пригодиться для повышения скорости работы в Apache Spark. В этой статье вы узнаете, как предотвратить перетасовку данных (shuffle), а также зачем стоит применять оконные функции, кэширование, бакетирование и контрольные точки.
1. Трансляция (broadcating) небольших таблиц при использовании операции join
Соединение нескольких таблиц — достаточно распространенная операция в Spark. В большинстве случаев она требует перетасовки (shuffle), которая является дорогостоящей операцией из-за перемещений данных между узлами. Но если одна из таблиц небольшая по размеру, то возможно никакой перетасовки не произойдет. Более того, с помощью трансляции (broadcating) небольшой таблицы по узлам в кластере перетасовки можно избежать.
Допустим, что у нас есть таблица под названием df_order, которая содержит информацию о заказах. Также есть другая таблица df_city, которая содержит информацию о городах, соответствующих заказу. Если в заказах более 100 миллионов строк и множество столбцов, то,вероятно, что количество городов не очень высокое, например, 100 строк. При добавлении информации о городах к таблице заказов мы можем добавить трансляцию, тогда никакой перетасовки не будет.
df = df_order.join(broadcast(df_city), on=['city_id'], how='inner')
Максимальный размер транслируемой таблицы составляет 8 Гб. Spark также поддерживает изменение границы размеров таблицы, при которых автоматически будет выполняться трансляция. Это делается через параметр spark.sql.autoBroadcastJoinThreshold, по умолчанию равный 10 Мб.
2. Замена операций соединения и агрегирования на оконные функции
Достаточно распространенным явлением является выполнение аргегирующих функций на столбцах и хранение полученных результатов в одной таблице в виде нового столбца, например, с помощью withColumn. В этом случае стоит использовать оконные функции (window functions). Вместо того, чтобы выполнять операции над всей таблицей, можно разбить её на партиции с их помощью.
# Агрегирование и соединение
df_agg = df.groupBy('city', 'team') \
.agg(F.mean('job').alias('job_mean'))
df = df.join(df_agg, on=['city', 'team'], how='inner')
# Применение оконной функции
from pyspark.sql.window import Window
window_spec = Window.partitionBy(df['city'], df['team'])
df = df.withColumn('job_mean', F.mean(col('job')) \
.over(window_spec)
3. Минимизация перетасовки в Apache Spark
Операторы в Spark представляются в виде конвейеров и выполняются в параллельных процессах. Однако перетасовка может разрушить этот конвейер. В конце каждого этапа все получившиеся результаты переходят на следующий этап. Внутри каждого этапа задачи выполняются параллельно.
Перетасовка данных — это перемещение данных по узлам. Данные в это время могут быть записаны. А операции ввода-вывода не самые быстрые (включая сериализацию данных), к тому же и пропускная способность сети ограничена (если данные ещё и по сети передаются). Преобразования join, groupBy, reduceBy, repartition и distinct выполняются с перетасовкой. Хотя перетасовка выполняется не всегда: если на предыдущем этапе преобразования уже произведены партиции, то перетасовки не будет.
Spark имеет три типа алгоритма операции соединения:
SortMergeJoin;ShuffleHashJoin;BroadcastHashJoin.
По умолчанию, начиная с версии 2.3, используется алгоритм SortMergeJoin. Можно указать BroadcastHashJoin для повышения производительности, но он имеет ограничения на размер таблицы.
При этом размеры данных при перетасовке имеют значение, в этом случае встает вопрос: выполнить одну большую перетасовку или несколько маленьких? Это зависит от ваших данных, иначе бы в Spark это было бы поведением по умолчанию.
Как правило, если каждая партиция первой таблицы используется в, как минимум, одной партиции второй таблицы при использовании операции соединения, то не возникает никакой нужды в перетасовке. Однако если каждая партиция первой таблицы может быть использована во множестве других партиций второй таблицы, тогда возникает необходимость в перетасовке. Таким образом, можно избежать перетасовки из-за повторной партиции или бакетировании (bucketing) обеих таблиц при использовании того же самого ключа до реализации соединения (о чем ниже). При этом сами эти операции также требуют перетасовки.
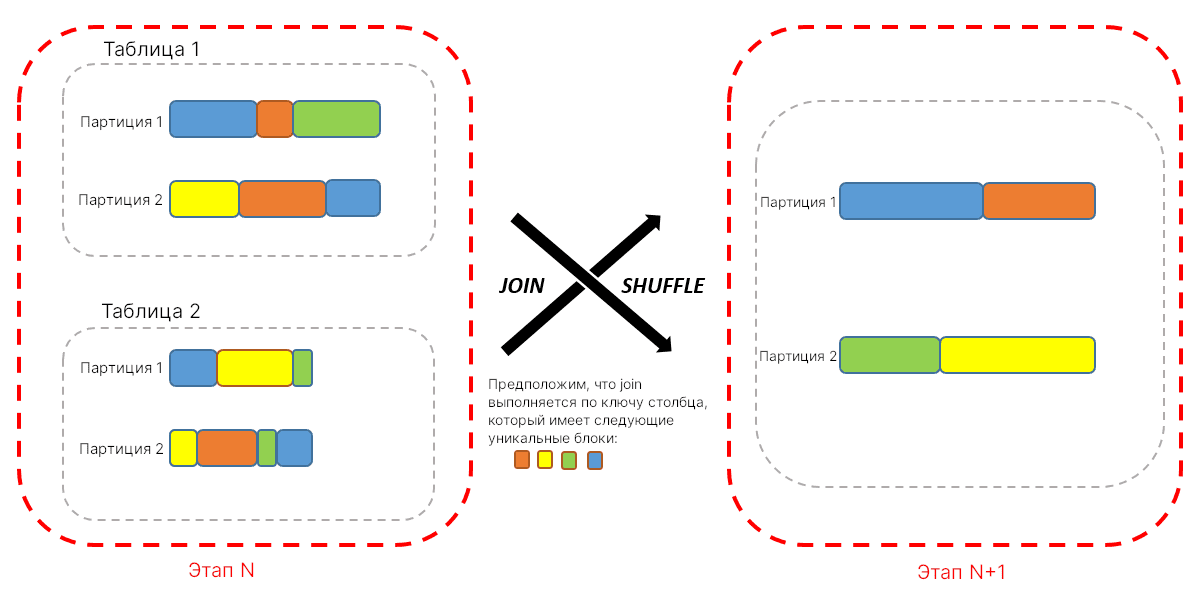
Типичным примером, когда используется меньше данных в перетасовке, может быть соединение одной большой и одной средней таблицы. Если средняя таблица недостаточно мала, чтобы быть транслированной, при этом столбцов немного, то мы можем транслировать их значения для фильтрации большой таблицы. Так, можно достичь меньшего объема данных, которые участвуют в перетасовке, ведь мы можем отфильтровать значительную часть данных из большой таблицы.
list_to_broadcast = df_medium \
.select('id') \
.rdd.flatMap(lambda x: x) \
.collect()
df_reduced = df_large.filter(df_large['id'].isin(list_to_broadcast))
df = df_reduced.join(df_medium, on=['id'], how='inner')
4. Бакетирование
Бакетирование (bucketing) — это другой метод организации данных, который заключается в группировке данных с одинаковым значением бакета, или ключом. Метод похож на разбиение партиций, но если Spark создает директории для каждой партиции, то бакетирование распространяет данные через фиксированное число бакетов, каждый из которых имеет свое хэш-значение. Информация о бакетировании находится в хранилище метаданных. При этом оно может использоваться как с партициями, так и без. Также партиции применяются только со столбцами, которые имеют ограниченное количество записей; бакетирование же работает и при больших количествах столбцов. Столбцы, которые часто применяются в операциях агрегации и соединений, — идеальные кандидаты для бакетирования.
Применение бакетирования на удобных столбцах перед операциями, которые требуют перетасовки, позволяет их избежать, поскольку оно уже само сортирует и перетасовывает данные. Важно, чтобы таблицы имели одно и то же число бакетов при их соединении.
Метод bucketBy принимает количество бакетов и имена столбцов (в виде строки, если это один; в виде списка, если это несколько), которые будут подвергнуты этой операцией.
df = df.bucketBy(32, 'key').sortBy('value')
5. Кэширование
Только потому, что у вас имеется возможность кэшировать данные, вы не должны делать это постоянно. Ведь память для выполнения и хранения одна и та же. Чем больше ненужных кэшей, тем больше шанс, что данные разместятся на диске, следовательно замедлятся операции.
Если таблица итеративно переиспользуется, то тогда следует кэшировать её в самом начале, чтобы избежать повторяющихся загрузок. Это идеальный случай использования кэширования.
Неправильное его использование можно наблюдать, когда, например, кэширование применяется сразу после чтения данных с Cassandra или Parquet. В этом случае все данные будут кэшированы без анализа нужно ли это делать или нет. Например, при чтения из parquet будут прочитаны только метаданные для получения их количества, поэтому не нужно сканировать весь датасет. При использовании запроса на фильтрацию оно подрезает таблицу и сканирует только необходимые столбцы. С другой стороны, при чтения данных из кэша Spark прочитает весь датасет.
И на заметку. Если вы применили даже маленькую транзакцию, например, добавили дополнительный столбец с помощью withColumn, то кэш больше не будет храниться. Статус хранения можно проверить через df.storageLevel.
6. Контрольные точки в Apache Spark
Контрольные точки (Checkpoint) обрезает план выполнения и сохраняет таблицу во временном хранилище на диске и выгружает их обратно. Каждый раз, когда применяется операция преобразования или выполняется запрос к таблице, план запросов растет. Spark хранит всю историю о примененных преобразованиях. Когда план запросов становится слишком большим, то производительность падает и образуется “бутылочное горлышко”.
Контрольные точки помогают обновить план запросов. Они хорошо работают в итеративных алгоритмах и при создании новых таблиц. После создания контрольной точки не нужно повторно проводить вычисления предыдущих шагов, поскольку они уже хранятся на диске. Заметим, что Spark не будет подчищать сохраненные данные, даже если sparkContext будет уничтожен, поэтому делать это нужно вручную.
Кэширование, с другой стороны, как альтернатива контрольной точке, нуждается в большем объеме памяти. Также стоит вопрос, где эти данные размещать в конвейере данных. Место размещения определяется при создании Spark-сессии.
# план запросо без контрольной точки df = df.filter(df['city'] == 'Ankara') df = df.join(df1, on = ['job_id'], how='inner') df.explain() # план запросо с контрольной точкой df = df.filter(df['city'] == 'Ankara').checkpoint() df = df.join(df1, on = ['job_id'], how=’inner’) df.explain()
Код курса
GRAS
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
В следующей статье рассмотрим еще несколько способов повышения производительности операций Apache Spark. Если хотите узнать о внутреннем строении Apache Spark и как писать оптимизированные запросы, то приходите на наши курсы в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков

