Классификация – одна из главных задач машинного обучения (Machine Learning). Сегодня рассмотрим один из линейных классификаторов Spark MLlib – метод опорных векторов (SVM). В этой статье применим метод опорных векторов для задачи бинарной классификации с примерами на Python API.
Классификация: бинарная и многоклассовая
Цель классификации – это разделить объекты на заданные категории. Самый обычный тип классификации – это бинарная классификация, т.е. когда всего два класса. А если классов больше, то уже решается задача многоклассовой классификации. Классификаторы, или алгоритмы классификации, могут быть линейными и нелинейными. Линейные классификаторы принимают решение на основании линейного оператора [1], т.е. разделяют классы прямой линией, плоскостью или другим многомерным линейный аналогом.
В Spark MLlib есть всего два линейных классификатора: метод опроных векторов (Support Vector Machines, SVM) и логистическая регрессия (logistic regression). Метод опорных векторов решает только задачу бинарной классификации, в то время как логистическая регрессия – и бинарную, и многоклассовую. Также оба этих алгоритма поддерживают L1- и L2-регуляризацию. После передачи данных алгоритму классификации Spark MLlib представляет входные данные в виде RDD из маркированных векторов (LabeledPoint, о которых говорили тут), где каждый маркер – это класс, который начинается с нуля: 0, 1, 2 и т.д.
Метод опорных векторов в Spark MLlib
Метод опорных векторов является одним из самых популярных алгоритмов машинного обучения. Функция потерь определяется формулой:
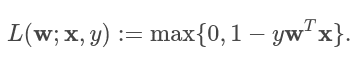
где w – это веса, x – входной вектор, y – класс (1 или -1). По умолчанию в Spark MLlib метод опорных векторов обучается с L2-регуляризацией.
Пример обучения SVM на Python
В качестве входных данных возьмем готовую выборку, которая предоставлена в официальном репозитории Apache Spark. Первым столбцом выборки является класс принадлежности (1 или 0), а остальные столбцы – признаки. Каждый столбец отделен пробелом. Представим выборку в формате RDD из LabeledPoint, где меткой будет класс, а вектором – признаки.
Пример кода для представления LabeledPoint в Apache Spark на основе входных данных выглядит следующим образом:
from pyspark import SparkConf, SparkContext
from pyspark.mllib.regression import LabeledPoint
conf = SparkConf() \
.setAppName("LinearClassification") \
.setMaster("local[*]")
sc = SparkContext(conf=conf)
def parsePoint(line):
values = [float(x) for x in line.split(' ')]
return LabeledPoint(values[0], values[1:])
data = sc.textFile("sample_svm_data.txt")
parsedData = data.map(parsePoint)
Теперь данные выглядят вот так:
LabeledPoint(0.0, [2.8,0.0,2.0,2.6,0.0,0.0,0.0,0.0,2.2,2.2]), LabeledPoint(1.0, [2.8,2.6,0.0,0.0,0.0,0.0,2.2,2.2,0.0,0.0]), LabeledPoint(1.0, [2.1,1.6,0.0,0.0,0.0,0.0,2.4,0.2,0.0,0.0]), # etc
Обучение алгоритма метода опорных вектор осуществляется через класс SVMWithSGD вызовом метода train. У этого метода много параметров, включая вид регуляризации [2]. Результатом обучения линейного классификатора SVM является объект SVMModel.
Пример кода для обучения метода опорных векторов в Apache Spark:
model = SVMWithSGD.train(parsedData)
На основе обученной модели SVMModel можно получить предсказания. Получим их в виде отдельного RDD с помощью метода map. А также посчитаем точность классификатора, поделив количество неправильных вариантов к общему количеству.
# lp - это объект LabeledPoint
labelsAndPreds = parsedData.map(lambda lp:
(lp.label, model.predict(lp.features))
)
trainErr = labelsAndPreds.filter(lambda lp: lp[0] != lp[1]).count()
trainErr = trainErr / parsedData.count()
# Точность равна 0.381
Чтобы сохранить модель машинного обучения Apache Spark, вызывается метод save; а чтобы воспользоваться сохраненной моделью, используется метод load:
from pyspark.mllib.classification import SVMWithSGD, SVMModel model.save(sc, "SVMWithSGDModel") sameModel = SVMModel.load(sc, "SVMWithSGDModel")
В следующей статье рассмотрим второй линейный классификатор Spark MLLib – логистическую регрессию. А еще больше подробностей о обучении линейных моделей и их применении на реальных примерах Data Science вы узнаете на специализированном курсе по машинному обучению «Машинное обучение в Apache Spark» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

