
В прошлый раз мы говорили про источники структурированных данных в Spark. Сегодня продолжим разговор про наборы RDD и рассмотрим на практических примерах особенности выполнения основных числовых операций с этими структурами данных.
Какие существуют числовые операции над наборами RDD: основные виды
Набор RDD (Resilient Distributed Dataset) представляет собой неизменяемую коллекцию объектов данных из строк произвольной длины. Они могут содержать как текстовые данные, так и числовые – наборы чисел, которые поддерживают следующие операции:
- нахождение общего числа элементов в наборе RDD;
- нахождение среднего значения по элементам;
- вычисление общей суммы элементов набора данных;
- нахождение минимального и максимального значений;
- вычисление дисперсии и стандартного отклонения.
Как все эти операции осуществляются на практике, мы подробно рассмотрим далее.
Основные виды операций с числовыми данными в наборах RDD
Методы выполнения числовых операции с RDD в Apache Spark поддерживаются модулем pyspark.sql.functions. Поэтому прежде всего его необходимо импортировать:
from pyspark.sql.functions import*
Для создания набора данных RDD используется метод parallelize():
my_RDD = sc.parallelize([1,3,7,9,5,4,6,8,999])
Чтобы подсчитать количество элементов в наборе, используется метод count():
my_RDD = sc.parallelize([1,3,7,9,5,4,6,8,999]) my_RDD.count()###9
Из примера видно, что метод возвращает число-счетчик, которое соответствует количеству элементов в наборе данных, начиная с 1. Для расчета суммы элементов используется метод sum():
my_RDD.sum() ###1042
Для поиска среднего значения можно использовать классическое деление суммы на количество элементов:
my_RDD.sum() / my_RDD.count() ###115.7777777
Однако, благодаря тому, что модуль pyspark.sql имеет в своем арсенале метод mean(), задача существенно упрощается. «Под капотом» метода mean() содержится счетчик количества элементов и их сумма для вычисления среднего значения элементов:
my_RDD.mean() ###115.777777777765
Стоит отметить, что при использовании встроенного метода mean() точность результата выше, чем при использовании «ручных» вычислений. Это говорит о том, что метод mean() работает гораздо эффективнее, чем «ручные вычисления».
В наборе данных RDD, который состоит из числовых данных, существует также возможность нахождения минимального и максимального значений с помощью методов min() и max() соответственно:
my_RDD.min() ###1 my_RDD.max() ###999
Бывают случаи, когда необходимо вычислить аномальные значения (outlier values) в наборе RDD во избежание некорректной работы алгоритмов машинного обучения. Для этого прежде всего необходимо вычислить дисперсию значений (variance) и их стандартное отклонение (standard deviation). Для вычисления дисперсии используется метод variance():
my_RDD.variance() ### 97515.72839506173
Метод stdev() применяется для вычисления стандартного отклонения:
my_RDD.stdev() ### 312.27508449292225
В модуле pyspark.sql существует также метод, «под капотом» которого находятся все вышеперечисленные методы. Он возвращает подробную статистику о данных:
my_RDD.stats()
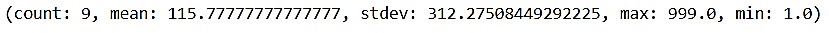
Для более наглядного использования всех вышеперечисленных методов можно вычислить и удалить аномальные значения в наборе RDD:
import math from pyspark.sql.functions import* my_RDD = sc.parallelize([1,3,7,9,5,4,6,8,999]) distanceNumerics = first_RDD.map(lambda string: float(string)) stats = distanceNumerics.stats() stddev = stats.stdev() mean = stats.mean() reasonableDistances = distanceNumerics.filter(lambda x: math.fabs(x - mean) < 3 * stddev) print (reasonableDistances.collect()) ### [1.0, 3.0, 7.0, 9.0, 5.0, 4.0, 6.0, 8.0]
Подводя итог всем рассмотренным методам работы с числовыми данными наборов RDD, отметим, что их разнообразие и точность работы позволяют фреймворку Apache Spark делать качественную подготовку данных для корректной работы алгоритмов машинного обучения. Поэтому Apache Spark активно используется в Data Science и разработке Big Data приложений. В следующей статье мы поговорим про аккумуляторы в Spark.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.

