
В прошлый раз мы говорили про архитектуру распределенной среды в Spark. Сегодня поговорим про особенности работы такого алгоритма машинного обучения, как случайный лес. Читайте далее про особенности работы со случайными лесами в Spark, благодаря которому Apache Spark имеет возможность Big Data анализа и классификации в распределенной среде.
Как работает алгоритм случайного леса: особенности классификации
Случайный лес (random forest) — это алгоритм машинного обучения, который заключается в использовании ансамбля (совокупности) деревьев решений (decision trees). Ключевая идея заключается в том, что качество классификации в случайном лесу повышается за счет большого количества ансамблей деревьев решений. Классификация проводится путем голосования деревьев, где каждое дерево относит классифицируемый объект к одному из классов. Побеждает тот класс, за который проголосовало наибольшее число деревьев. Оптимальное число деревьев подбирается таким образом, чтобы минимизировать ошибку классификации на тестовой выборке. В случае отсутствия ошибки, минимизируется оценка ошибки на образцах, не вошедших в набор [1].
Алгоритм случайного леса в Spark: несколько практических примеров
Для того, чтобы начать работу со случайным лесом, необходимо настроить базовую конфигурацию, импортировав некоторые классы ml-библитоеки Spark [2]:
# библиотека векторизации признаков from pyspark.ml.feature import VectorAssembler # библиотека оценки регресии from pyspark.ml.evaluation import RegressionEvaluator # библиотека алгортима случайного леса from pyspark.ml.regression import RandomForestRegressor
В качестве датасета будем использовать данные о кредитовании, в котором каждая запись представляет хорошего (creditability=1) и плохого (creditability=0.) заемщика на основании его личных данных (например, возраст, кредитная история, сумма кредита и т.д.) Датасет можно сказать из источника здесь.
В первую очередь необходимо прочитать датасет с помощью pyspark [2]:
inputData = spark.read.csv("credit.csv", inferSchema=True, header=True)
Далее необходимо сформировать вектор признаков путем их векторизации с помощью класса VectorAssembler. Векторизованные признаки назовем features [2]:
assembler = VectorAssembler( inputCols=["amount", "savings", "assets", "age", "credits"], outputCol="features") output = assembler.transform(inputData)
После векторизации необходимо разбить выборку на обучающую и тестовую (стандартно, 70:30 соответстсвенно) [2]:
train, test = output.randomSplit([0.7, 0.3])
Далее применим модель случайного леса (за это отвечает класс RandomForestRegressor() и обучим ее на обучающей выборке данных с помощью метода fit() [2]:
rf = RandomForestRegressor(featuresCol="features", labelCol='creditability', numTrees=10) rfModel = rf.fit(train)
В качестве параметров конструктора класса у экземпляра RandomForestRegressor() используются следующие:
featuresCol— колонка, содержащая вектор признаков, на основе которых ведется предсказание или классификация;labelCol— колонка целевой переменной, для которой идет предсказание (классификация)numTrees— количество деревьев, участвующих в классификации.
Для предсказания (или классификации) используется метод transform(). Следующий код на языке Python отвечает за формирование датасета с предсказаниями:
predictions = rfModel.transform(test)
Для оценки модели будем использовать регрессионный оценщик (класс RegressionEvaluator), который включает в себя следующие свойства:
labelCol— колонка, по которой велось предсказание или классификация;predictionCol— колонка, содержащая набор с предсказаниями;metricName— название метрики для оценки модели (в нашем случае для оценки используется среднеквадратичная ошибка (Root Mean Squared Error, RMSE)).
Следующий код на движке pyspark отвечает за формирование оценки модели [2]:
evaluator = RegressionEvaluator(
labelCol="creditability", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print("Root Mean Squared Error (RMSE) on test data = %g" % rmse)
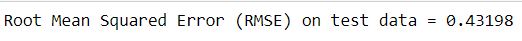
Таким образом, благодаря поддержке алгоритма случайных лесов, Spark имеет возможность проводить классификацию в распределенной среде, используя огромные массивы данных для обучения, что может способствовать обучению весьма эффективных моделей. Все это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники

