
В прошлый раз мы говорили про особенности взаимодействия Big Data фреймворка Spark с реляционными СУБД. Сегодня поговорим о том, как Spark обрабатывает данные, которые подаются в виде структуры формата JSON (Java Script Object Notation). Читайте далее про особенности работы с JSON-файлами в распределенной среде фреймворка Apache Spark.
Особенности работы Spark со структурированными JSON-файлами
JSON (Java Script Object Notation) — это текстовый формат данных, основанный на языке JavaScript. Однако несмотря на происхождение от JavaScript, формат считается независимым от языка и может использоваться в качестве обрабатываемой структуры данных с любым языком программирования (например, Java, Python, Scala). В качестве значений в JSON могут быть использованы следующие элементы:
- запись — это множество пар ключ/значение, заключенное в фигурные скобки;
- одномерный массив — это упорядоченное множество значений, заключенное в квадратные скобки. Значения массива разделяются между собой запятыми. Значения в пределах одного JSON-массива могут иметь разный тип;
- литералы — элементы, имеющие буллевский (boolean) тип и принимающие значения true (истина) или false (ложь);
- строка — это упорядоченное множество из нуля или более символов, заключенных в двойные кавычки [1].

Работа с JSON-файлами в Spark: несколько практических примеров
Для того, чтобы прочитать JSON-файл в Spark используется метод json(), который в качестве параметра принимает путь до файла, включая сам файл:
json_data = spark.read.json('file.json')
Однако в большинстве случаев необходимо прочитать несколько JSON-файлов за один раз, поэтому необходимо настроить параметр для мультистрок (multiline). Для этого необходимо во время чтения вызвать метод option() и указать в качестве параметра multiline, а в методе json() указать путь до папки (директории) с файлами:
json_data = spark.read.option("multiline",True).json('files')
После чтения JSON-файла Spark автоматически создает датафрейм. Зачастую один ключ может иметь несколько значений, некоторые из которых являются массивами. Для того, чтобы получить значения конкретного массива, необходимо в методе select() указать название ключа и через точку указать название массива, который содержит данный ключ:
json_data.select('elements.companyGroupShortInfo.groupID').show()
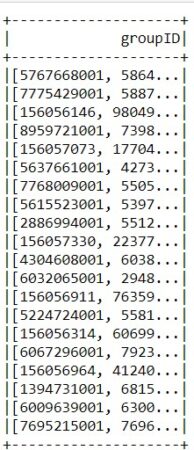
Зачастую случается так, что значения представлены в виде многомерного массива и явно получить доступ к его элементам не получится. Для этого в Spark существует специальный метод explode(), позволяющий разбить многомерный массив на одномерные и работать с каждым массивом по отдельности. Следующий код на языке Python позволяет разбить многомерный массив значений ключа businessRegion и получить имена областей (name):
json_data.select(explode('elements.companyGroupShortInfo.businessRegions.businessRegion')\
.alias ('b')).select('b.name').show()

Таким образом, благодаря методам работы с JSON-файлами, фреймворк Spark способен обрабатывать огромное количество структурированных Big Data документов в распределенной среде. Это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика распределенных Big Data приложений. В следующей статье мы поговорим про деревья решений в Spark.
Больше подробностей про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
Источники

