Мы уже рассматривали базовые функции для работы с датафреймами в Apache Spark. Сегодня поговорим о том, какие функции используются при детальном анализе данных в датафреймах (dataframe) Spark, рассмотрев несколько практических примеров.
3 функции для расширенной работы с датафреймами в Apache Spark
Фреймворк Apache Spark позволяет проводить углубленный анализ данных при работе с датафреймами с помощью специальных функций для преобразования данных с целью их наглядного представления. Наиболее востребованными из этих функций можно назвать следующие:
- удаление дубликатов;
- сортировка;
- функции агрегации.
Каждую из этих функций мы подробнее рассмотрим далее.
Агрегация датафреймов в Apache Spark
Функции агрегации служат для объединения всех элементов столбца датафрейма и выполнения последующих преобразований над ними. К функциям агрегации относятся следующие:
count– нахождение количества элементов;max– нахождение наибольшего значения;min– нахождение минимального значения;mean– нахождение среднего значения (для числовых типов);sum– нахождение суммы всех элементов столбца (для числовых типов).
Для того, чтобы применить агрегирующую функцию, необходимо вызвать метод agg(), а затем в качестве параметра передать пару {столбец: функция}. В качестве примера найдем сумму возрастов всех людей:
my_schema=StructType([StructField('id',IntegerType(),True),\
StructField('name',StringType(),True),\
StructField('age',IntegerType(),True),\
StructField('country',StringType(),True),])
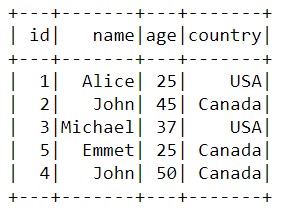
data_2=spark.createDataFrame([(1,'Alice',25,'USA'),(2,'John',45,'Canada'),(3,'Michael',37,'USA)',
(4,'John',50,'Canada'),
(5,'Emmet',25,'Canada')],\
['id','name','age','country'],my_schema)
data_2.agg({'age':'sum'}).show()
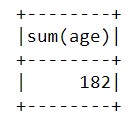
А теперь давайте выясним, сколько лет самому старшему и самому младшему человеку:
data_2.agg({'age':'min'}).show()
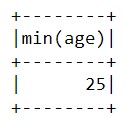
data_2.agg({'age':'max'}).show()
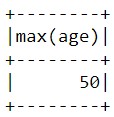
Мы также можем также узнать средний возраст всех людей с помощью функции mean:
data_2.agg({'age':'mean'}).show()
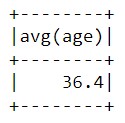
А теперь определим, сколько всего данных о возрастах было представлено с помощью функции count:
data_2.agg({'age':'count'}).show()
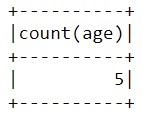
Таким образом, мы видим, что с помощью агрегирующих функций можно работать с множеством данных, как с одним элементом.
Удаление дубликатов
Удаление дубликатов – это функция, которая позволяет убрать повторяющиеся значения, не имеющие отношения к основным данным. Как правило, такие значения рекомендуется удалять, так как они занимают дополнительные ресурсы, замедляя процесс анализа, а также приводят к некорректным результатам. Для удаления дубликатов используется функция distinct(). Давайте уберем дубликаты с помощью этой функции:
duplicate_data = data_2 duplicate_data.show() clear_data = duplicate_data.distinct().show()

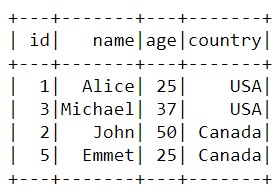
Таким образом, данные уменьшились вдвое. Это означает, что мы освободили половину ресурсов.
Сортировка данных
Сортировка данных – это расположение данных в наиболее удобном порядке для более наглядного их отображения. Для примера давайте отсортируем наши данные по числовому столбцу в убывающем порядке с помощью функции orderBy():
sorted_data = data_2.orderBy('age',ascending=False).show()
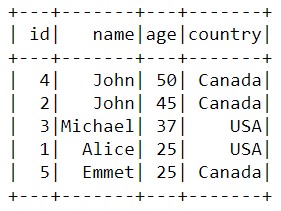
Сортировать данные можно не только по числам, но и по строкам. В таком случае порядок сортировки будет определяться числовыми индексами, которые соответствуют порядковым номерам символов в алфавите:
sorted_data=data_2.orderBy('name',ascending=False).show()
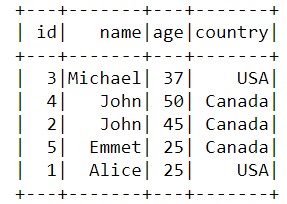
Таким образом, благодаря функциям для расширенной работы с данными, Apache Spark позволяет вести детальный анализ данных, что делает его весьма полезным инструментом для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы продолжим говорить про датафреймы и рассмотрим взаимодействие Spark и Pandas.
Более подробно про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.

