
В прошлый раз мы говорили о том, как Spark работает с файлами. Сегодня поговорим о том, какие функции являются базовыми при работе с датафреймами (dataframe) в Apache Spark. Также подробно рассмотрим эти функции на практических примерах.
3 базовых функции для работы с датафреймами в Apache Spark
Фреймворк Apache Spark, также, как и Pandas, имеет возможность работы с данными посредством создания датафрейма. Датафрейм (dataframe) – это двумерная маркированная структура данных. Визуально она представляет собой таблицу, состоящую из фиксированного числа строк и столбцов. Датафрейм служит для быстрой и удобной работы с большими данными. Существует ряд функций, которые являются основой для эффективного анализа и работы с данными датафреймов в Apache Spark. Среди них наиболее известны следующие:
- создание датафрейма;
- группировка данных;
- выборка данных.
Каждую из этих функций мы подробнее рассмотрим далее.
Функции создания датафрейма
Создание датафрейма – это приведение данных к двумерному табличному виду для последующей работы с ними. Создавать датафрейм в Spark можно двумя способами:
- вручную;
- загрузить данные из внешнего источника, например, из файла.
Для того, чтобы создать датафрейм вручную, рекомендуется заранее определить типы данных для того, чтобы в будущем избежать конфликтов с их несовместимостью. Для создания датафрейма вручную используется метод spark.createDataFrame():
my_schema=StructType([StructField('id',IntegerType(),True),\
StructField('name',StringType(),True),\
StructField('age',IntegerType(),True),\
StructField('country',StringType(),True),])
data_1=spark.createDataFrame([(1,'Alice',25,'USA'),(2,'John',32,'Canada')],\
['id','name','age','country'],my_schema)
Мы можем посмотреть, как выглядит наш датафпейм, используя метод show():
data_1.show()

А теперь давайте посмотрим, как можно загрузить данные из внешнего источника, создав датафрейм. В качестве примера загрузим данные из csv-файла с помощью метода spark.read.option().csv():
data_1 = spark.read.option('header','True').csv('info_data.csv',sep=',')
data_1.show()
Группировка данных в датафрейме
Группировка данных – это сбор уникальных данных в группы для последующего применения к ним агрегирующих функций, таких как, например, нахождение среднего значения для каждой группы, число значений для каждой группы и т.д. Для того, чтобы сгруппировать данные в датафрейме, используется метод groupBy (аналог GROUP BY в SQL). Давайте рассмотрим пример группировки данных и найдем, сколько человек проживает в каждой стране. Для этого нам нужно сгруппировать наши данные по столбцу “country”:
data_1.groupBy('country')
Таким образом, мы получили нужные нам сгруппированные данные. Обратим внимание, что эти данные не являются датафреймом, а это означает, что мы не сможем работать с такими данными как с датафреймом. Давайте в этом убедимся и посмотрим на тип этих данных с помощью функции type():
type(data_1.groupBy('country')) ### pyspark.sql.group.GroupedData
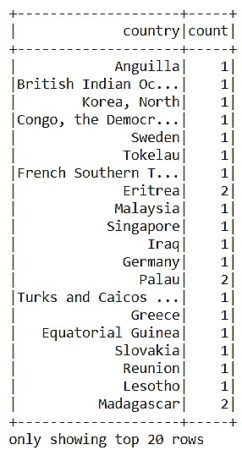
Как мы видим, для таких данных в Spark есть специальный тип GroupedData. Для того, чтобы данные вновь стали датафреймом, необходимо применить к ним агрегирующую функцию. Давайте, наконец, посчитаем сколько человек проживает в каждой из стран с помощью агрегирующей функции count():
data_1.groupBy('country').count().show()
Выборка данных в датафрейме
Выборка данных в Spark-датафрейме – это формирование нового датафрейма на основе отбора необходимых столбцов из предыдущего. Для выборки данных в Apache Spark, как и в SQL существует специальный метод select(). Давайте посмотрим, как он работает в PySpark на практическом примере:
data_1.select('country','name','last_name').show()
В Spark также существует возможность выборки данных с условием. Для этого метод select() вызывается совместно с методом задачи условия where(). В качестве примера давайте получим информацию о людях, которые проживают в Бангладеш:
data_1.select('country','name','last_name').where(col('country')=='Bangladesh').show()

Таким образом, благодаря базовым функциям работы с данными датафреймов, Apache Spark позволяет вести анализ больших данных в более привычном и удобном формате, что делает его весьма полезным инструментом для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы продолжим говорить про датафреймы в Spark и рассмотрим функции сортировки данных, агрегации и удаления дубликатов.
Более подробно про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.

