Оконные функции (window functions) — один из полезных инструментов для обработки и анализа данных в PySpark. В этой статье на примере простых функций first_value и last_value мы покажем вам в чем разница между границами rows и range.
Исходные данные
Мы не будем брать сторонние датасеты, а вместо этого просто создадим свой из списков:
data = [
(1, "Alexander", "Admin", 3500),
(2, "Roman", "IT", 4500),
(3, "Tom", "IT", 5500),
(4, "Alex", "HR", 3000),
(5, "Arthur", "Finance", 4250),
(6, "Anna", "Finance", 3520),
(7, "Svetlana", "Admin", 3000),
(8, "Oleg", "IT", 3200),
(9, "Felix", "IT", 5500),
(10, "Olga", "IT", 4970),
(11, "Anna", "Finance", 6320),
(12, "Tom", "HR", 3500),
(13, "Felix", "Finance", 3520),
(14, "John", "Admin", 3500),
(15, "Finn", "IT", 5570),
(16, "Polly", "HR", 3800),
]
schema = ["id", "emp_name", "dept_name", "salary"]
df = spark.createDataFrame(data, schema)
Всегда можно сохранить DataFrame в виде таблицы, к которой можно выполнять SQL-запросы:
df.createTempView("work")
FIRST присваивает строке первое значение в PySpark
Функция FIRST_VALUE выбирает значение первой строки в партиции и присваивает его каждой записи нового столбца.
Возьмем, например, id самых высокооплачиваемых сотрудников каждого отдела. Тогда SQL-запрос выглядит так:
SELECT *,
FIRST_VALUE(id)
OVER(PARTITION BY dept_name
ORDER BY salary DESC) as richest_id,
FROM work
Тот же самый запрос в PySpark:
import pyspark.sql.functions as F
from pyspark.sql import Window
w = Window.partitionBy("dept_name").orderBy(F.desc("salary"))
df.withColumn("richest_id", F.first("id").over(w)).show()
"""
+---+---------+---------+------+----------+
| id| emp_name|dept_name|salary|richest_id|
+---+---------+---------+------+----------+
| 16| Polly| HR| 3800| 16|
| 12| Tom| HR| 3500| 16|
| 4| Alex| HR| 3000| 16|
| 11| Anna| Finance| 6320| 11|
| 5| Arthur| Finance| 4250| 11|
| 6| Anna| Finance| 3520| 11|
| 13| Felix| Finance| 3520| 11|
| 1|Alexander| Admin| 3500| 1|
| 14| John| Admin| 3500| 1|
| 7| Svetlana| Admin| 3000| 1|
| 15| Finn| IT| 5570| 15|
| 3| Tom| IT| 5500| 15|
| 9| Felix| IT| 5500| 15|
| 10| Olga| IT| 4970| 15|
| 2| Roman| IT| 4500| 15|
| 8| Oleg| IT| 3200| 15|
+---+---------+---------+------+----------+
"""
Это именно то, что мы ожидали. В отделе HR самая богатая — Poly c номером 16, в отделе IT — Finn с номером 15 и т.д.
В PySpark есть еще и LAST_VALUE. На первый взгляд кажется, что если заменить FIRST_VALUE на LAST_VALUE, то получим номера самых низкооплачиваемых сотрудников. Попробуем это сделать:
df.withColumn("poorest_id", F.last("id").over(w)).show()
"""
+---+---------+---------+------+----------+
| id| emp_name|dept_name|salary|poorest_id|
+---+---------+---------+------+----------+
| 16| Polly| HR| 3800| 16|
| 12| Tom| HR| 3500| 12|
| 4| Alex| HR| 3000| 4|
| 11| Anna| Finance| 6320| 11|
| 5| Arthur| Finance| 4250| 5|
| 6| Anna| Finance| 3520| 13|
| 13| Felix| Finance| 3520| 13|
| 1|Alexander| Admin| 3500| 14|
| 14| John| Admin| 3500| 14|
| 7| Svetlana| Admin| 3000| 7|
| 15| Finn| IT| 5570| 15|
| 3| Tom| IT| 5500| 9|
| 9| Felix| IT| 5500| 9|
| 10| Olga| IT| 4970| 10|
| 2| Roman| IT| 4500| 2|
| 8| Oleg| IT| 3200| 8|
+---+---------+---------+------+----------+
"""
Как видим мы получили не то, что хотели. Ведь в HR-отделе зарабатывает меньше всего Alex, однако на самой первой позиции полученного столбца стоит номер 16. Чтобы понять почему так, нужно разобраться в работе оконных функций (window functions), а именно, что такое фрейм,
Что такое фрейм и окно
Когда вызываются оконные функции, то создается окно, или партиция. В примерах этих окон было 3: ровно столько, сколько отделов (окно может состоять из всей таблицы, если не указано разбиение на партиции). Для каждого окна можно определить еще некоторую подгруппу строк, которая называется фреймом.
Когда мы применяем любую оконную функцию, то она применяется к фрейму. Мы можем менять эти фреймы через ROWS и RANGE.
По умолчанию фрейм определяется следующим образом:
SELECT *,
LAST_VALUE(id)
OVER(PARTITION BY dept_name
ORDER BY salary DESC
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
as poorest_id
FROM work
Этот запрос выдаст тот же самый результат, что и выше, но здесь мы явно добавили RANGE BETWEEN.
UNBOUNDED PRECEDING говорит нам о том, что считать нужно от первой строки партиции. А CURRENT ROW говорит о том, что фрейм заканчивается на текущей строке.
Давайте рассмотрим строки окна с HR. В первой строке с Poly фреймом является это же строка. Во второй строке текущая строка (current row) является эта строка, а абсолютная предшествующая (unbounded preceding) — первая. Это значит, что фрейм состоит из двух строк и результатом last_value является значение второй строки. Третий фрейм состоит из трех строк, где текущая — третья, а абсолютная предшествующая — первая, поэтому последним значением является значение третей строки. Аналогично происходит для каждой партиции.
Когда же используется функция first_value, то unbounded preceding и является тем самым первым значением, поэтому функция работает так, как мы ожидаем.
Указываем диапазон всего окна в PySpark
Чтобы сделать так, что функция last_value брала последнее значение партиции, нам нужно изменить фрейм.
Мы не можем считать от конца, но мы можем указать диапазон в виде всей партиции. Для каждой строки нужно рассматривать фрейм не от текущего значения, а в виде всего окна. Следовательно, вместо current row нужно указать абсолютное последующее unbounded following:
SELECT *,
LAST_VALUE(id)
OVER(PARTITION BY dept_name
ORDER BY salary DESC
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
as poorest_id
FROM work
Или в PySpark:
w = Window.partitionBy("dept_name") \
.orderBy(F.desc("salary")) \
.rangeBetween(Window.unboundedPreceding,
Window.unboundedFollowing)
df.withColumn("poorset_id", F.last("id").over(w)).show()
"""
+---+---------+---------+------+----------+
| id| emp_name|dept_name|salary|poorset_id|
+---+---------+---------+------+----------+
| 16| Polly| HR| 3800| 4|
| 12| Tom| HR| 3500| 4|
| 4| Alex| HR| 3000| 4|
| 11| Anna| Finance| 6320| 13|
| 5| Arthur| Finance| 4250| 13|
| 6| Anna| Finance| 3520| 13|
| 13| Felix| Finance| 3520| 13|
| 1|Alexander| Admin| 3500| 7|
| 14| John| Admin| 3500| 7|
| 7| Svetlana| Admin| 3000| 7|
| 15| Finn| IT| 5570| 8|
| 3| Tom| IT| 5500| 8|
| 9| Felix| IT| 5500| 8|
| 10| Olga| IT| 4970| 8|
| 2| Roman| IT| 4500| 8|
| 8| Oleg| IT| 3200| 8|
+---+---------+---------+------+----------+
"""
Кстати, этот запрос правильно сработает также и для FIRST_VALUE.
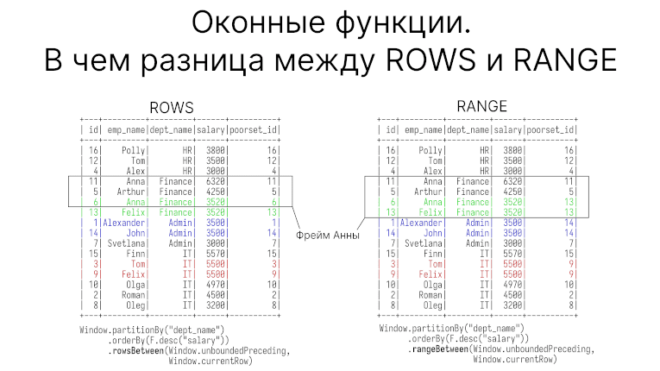
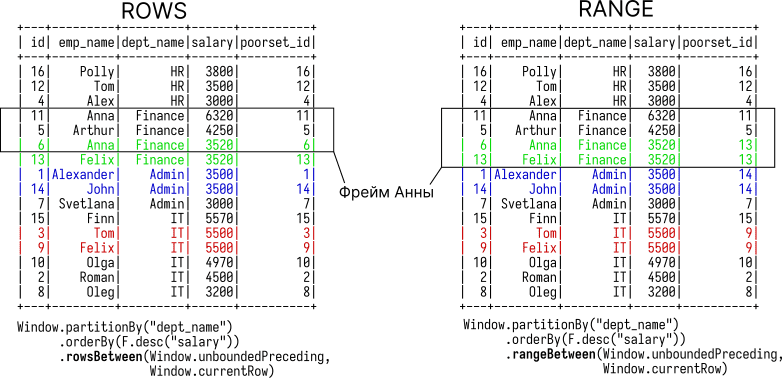
ROWS BETWEEN от RANGE отличаются тем, как работают с дубликатами
Помимо границ фрейма RANGE существует ROWS. Отличаются они тем, как рассматривают дубликаты в столбце, преданному ORDER BY.
При использовании ROWS записи с одинаковым значением в ORDER BY рассматриваются как отдельные строки. При использовании RANGE — как одна строка.
Взгляните еще раз на таблицу. В отделе финансов два сотрудника, Anna и Felix, имеют одинаковую зарплату. В отделе администраторов — Alexander и John. В отделе ИТ — Tom и Felix.
Если мы создаем фрейм от текущей строки, то в RANGE для одинаковых значениях фрейм будет отсчитываться от самой последней строки этих дубликатов. Ниже на рисунке это показано. На нем видно, что фрейм для Анны считается от Феликса; то же самое и для Александра и Тома.
Свои значения в PRECEDING и FOLLOWING в PySpark
Мы не спроста назвали UNBOUNDED абсолютным. UNBOUNDED PRECEDING означает первую строку партиции, UNBOUNDED FOLLOWING — последнюю. Мы также вольны указывать свои границы фрейма. В этом случае вместо UNBOUNDED нужно указать свое.
Например, в коде ниже фрейм будет определяться от одной строкой выше и одной строкой ниже относительно текущей. Заметим, что предыдущее значение должно быть отрицательным, это отличает PySpark от чистого SQL.
w = Window.partitionBy("dept_name") \
.orderBy(F.desc("salary")) \
.rowsBetween(-1, 1)
df.withColumn("first", F.first("id").over(w)) \
.withColumn("last", F.last("id").over(w)).show()
"""
+---+---------+---------+------+-----+----+
| id| emp_name|dept_name|salary|first|last|
+---+---------+---------+------+-----+----+
| 16| Polly| HR| 3800| 16| 12|
| 12| Tom| HR| 3500| 16| 4|
| 4| Alex| HR| 3000| 12| 4|
| 11| Anna| Finance| 6320| 11| 5|
| 5| Arthur| Finance| 4250| 11| 6|
| 6| Anna| Finance| 3520| 5| 13|
| 13| Felix| Finance| 3520| 6| 13|
| 1|Alexander| Admin| 3500| 1| 14|
| 14| John| Admin| 3500| 1| 7|
| 7| Svetlana| Admin| 3000| 14| 7|
| 15| Finn| IT| 5570| 15| 3|
| 3| Tom| IT| 5500| 15| 9|
| 9| Felix| IT| 5500| 3| 10|
| 10| Olga| IT| 4970| 9| 2|
| 2| Roman| IT| 4500| 10| 8|
| 8| Oleg| IT| 3200| 2| 8|
+---+---------+---------+------+-----+----+
"""
Также в Spark 3.1 была, наконец, добавлена функция nth_value, которая вместо первого или последнего значения выбирает заданное n-ое число.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400 руб.
А еще больше подроботсей о использовании оконных функций вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и IT-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков

