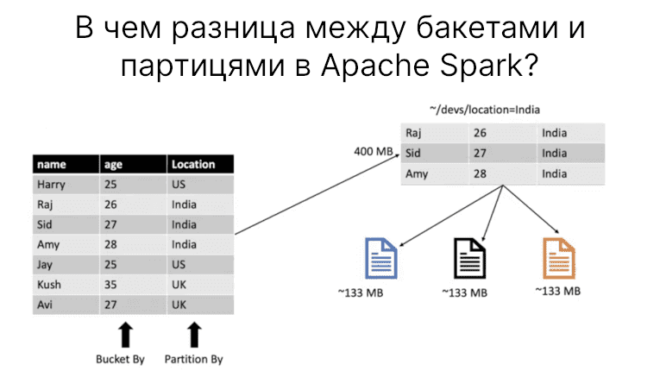
При оптимизации работы Apache Spark рекомендуют делать партиции и бакеты. Однако в чем разница между партицированием и бакетированием? В этой статье мы разберемся в этом.
Что такое партиции (partitions)?
В Spark можно разбить на партиции и бакеты, но в чем между ними разница? Партицирование разделяет большие данные на множество частей на основе значений столбца(ов).
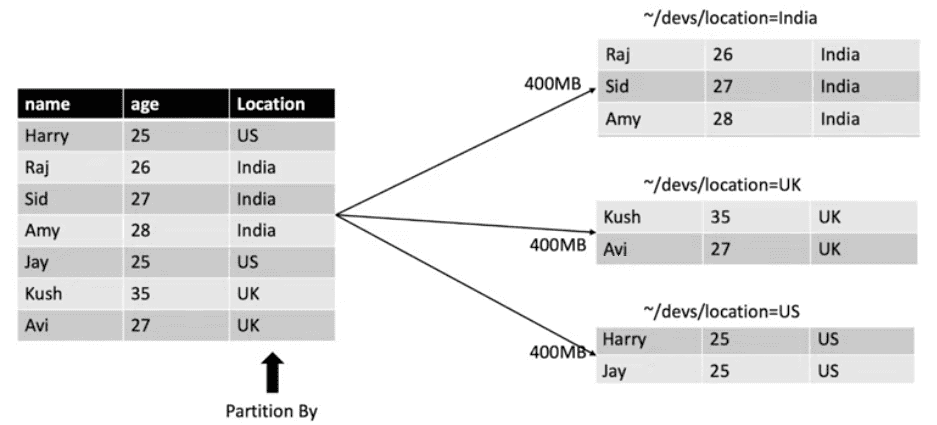
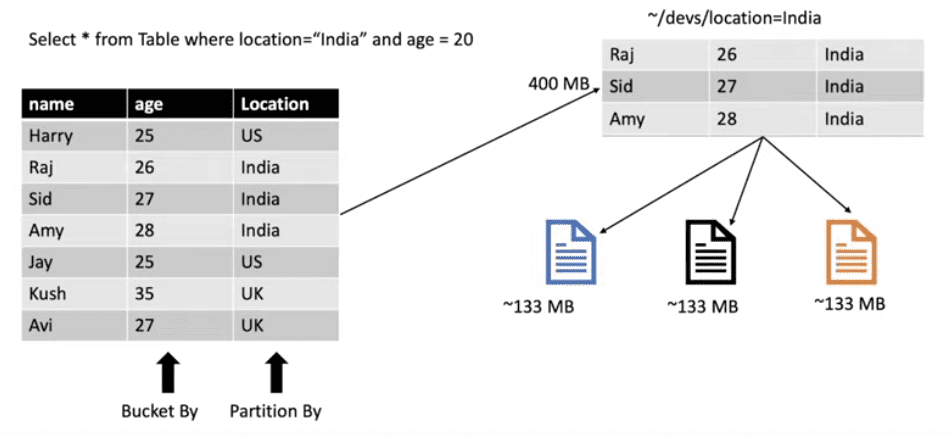
Например, представим, что храним информации о всех жителях Земли, живущих в 196+ стран. Если нужно запросить только информацию о жителях заданной страны (например, Ватикана), то без партиций придется пройтись по всем странам для фильтрации. Но мы можем разбить на партиции по странам. При использовании partitionBy под каждую партицию создается директория с соответствующими записями столбцов.
Минусы партицирования:
- Вредно иметь много партиций (операции ввода-вывода медленные, а при использовании
partitionByбудут созданы файлы); - Не решает проблему неравномерности данных (партиции могут быть разного размера, например, количество записей с населением Китая и Ватикана разное).
Что такое бакеты (backets)?
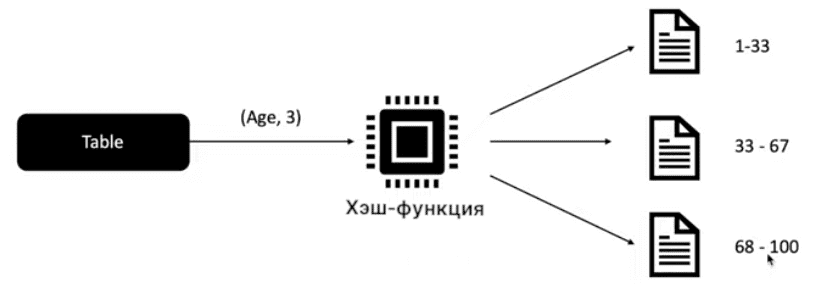
Бакетирование разбивает данные на части, количество которых задается пользователем. Вместо уникальных значений столбца бакетирование стремится разделить данные на равные части, где каждой части присваивается свой ключ на основе вычисления хэш-функции.
При использовании партицирования может произойти такое, что создастся много маленьких партиций с записями. А при использовании бакетирования вы сами ограничиваете это количество.
Совет здесь таков: категориальные значения лучше разбивать на партиции, а непрерывные на бакеты. Партиции можно также разбить на бакеты, а вот бакеты на партиции нельзя.
При этом надеется, что получатся бакеты примерно одинакового размера, не приходится. Например, представьте, что людей возрастом от 0 до 20 лет очень мало, а при этом от 20 до 40 много, причем 40 – это крайнее значение. Тогда разбиение на два бакета даст две неравных части.
Ниже таблица, которая показывает разницу между партицированием и бакетированием.
| Партицирование (Partitioning) | Бакетирование (Bucketing) |
|---|---|
| Распределяет данные по строкам | Делит данные на части |
| Количество партиций зависит от количества уникальных значений | Количество заранее задается |
| Подходит для категориальных значений | Подходит для непрерывных значений |
| Хранит данные статически и динамически | Хранит данные динамически |
| Выполнение будет быстрым при небольших размерах партиций | Операции map на бакетах будут быстрыми |
| Нет возможности хранить данные в отсортированном порядке для каждой партиции | Есть возможность хранить данные в отсортированном порядке для каждой бакета |
| Партиции могут быть разбиты на бакеты | Бакеты не могут быть разбиты на партиции |
Код курса
SPOT
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Больше подробностей о партициях и бакетах вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков

