
В Apache Spark есть функции для кэширования промежуточных данных с целью получения повышения производительности при выполнении SQL запросов. В этой статье мы сравним различные методы...

3 совета по ускорению Apache Spark
В прошлой статье мы говорили об устройстве оптимизатора Apache Spark. Теперь мы знаем, как сложный и продуманный механизм оптимизации Spark обеспечивает быстрый и эффективный анализ...

Как работает SparkSQL изнутри и причем здесь Catalyst
Spark обрабатывает данные быстро. Это было основным преимуществом фреймворка с момента его первого представления в 2010 году. Обладая широким спектром вариантов возможностей и простотой использования,...
3 метода параллельной обработки данных в Spark
Spark, как инструмент анализа данных, отлично подходит при увеличении масштаба задач и при увеличении размера самих данных Пока вы используете датафреймы и библиотеки Spark вы...

Выбор наилучшей модели: кросс-валдиация и разбиение на выборки
Тюнинг, или подбор параметров, является незаменимой частью при подборе модели Machine Learning, поскольку с одними параметрами модель может показывать высокие результаты, а с другими —...

Конвейеры машинного обучения в Spark
Построение моделей машинного обучения в Spark — это последовательный процесс. Сегодня мы расскажем о конвейерах (Pipeline) в Spark. Читайте далее: какие объекты используются в конвейере,...

10 вопросов на знание основ работы с RDD в Spark: открытый интерактивный тест для начинающих
Чтобы самостоятельное обучение по Spark стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы с наборами RDD в распределенном фреймворке Apache Spark,...
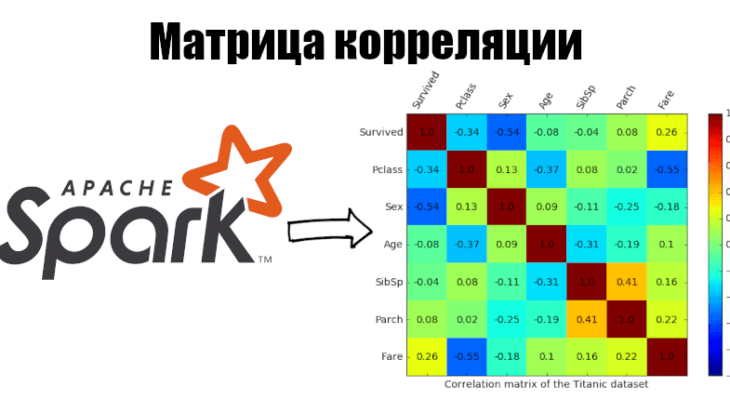
Статистка в Spark: корреляция
В рамках анализа данных и отбора признаков нередко вычисляется корреляция между признаками. Сегодня мы разберем, что такое корреляция, какие методы вычисления существуют, как найти коэффициенты...

10 вопросов на знание основ архитектуры Spark SQL: открытый интерактивный тест для начинающих
Чтобы самостоятельное обучение по Spark стало еще интереснее, сегодня мы предлагаем вам простой тест по основам архитектуры компонента Spark SQL, включая элементы, из которых она...

Как происходит сериализация данных в Spark
В прошлый раз мы говорили про популярные инструменты для сборки распределенных Spark-приложений. Сегодня поговорим про сериализацию данных распределенных приложений, созданных на базе Big Data фреймворка...