В прошлой статье мы говорили о таком линейном алгоритме машинного обучения (Machine Learning), как метод опорных векторов. Сегодня рассмотрим второй линейный классификатор Spark MLlib – логистическую регрессию. В отличие от SVM, логистическая регрессия может применяться для решения задач многоклассовой классификации.
Многоклассовая классификация с помощью логистической регрессии Spark MLlib
Как уже было сказано в прошлой статье, метод опорных векторов определяет только два класса. Поэтому если классов больше применяют другой линейный классификатор – логистическую регрессию. Функцией потерь логистической регрессии определяется как:
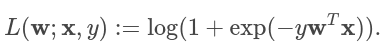
где w – это веса, x – входной вектор, y – класс принадлежности. При бинарной классификации алгоритм возвращает бинарную логистическую модель. Эта модель выдает предсказания на основе логистической функции на новых данных (тестовых) X :
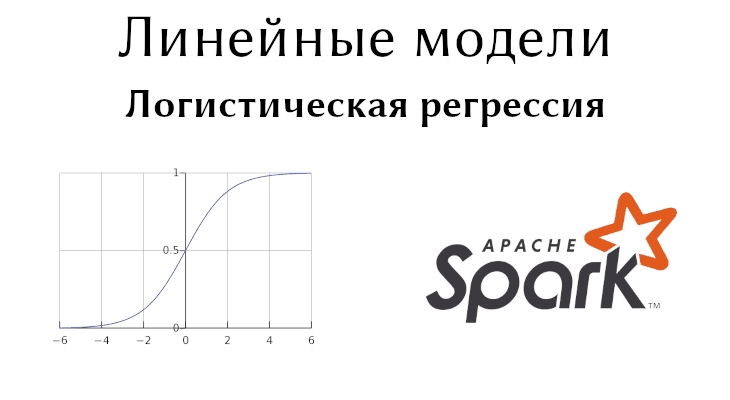
где z=wX. По умолчанию если f(z) > 0.5, то результат положительный и отрицательный, если f(z) <= 0.5. Можно заметить, что в отличие от метода опорных векторов, логистическая регрессия выдает вероятность принадлжености классу.
Бинарная логистическая регрессия можно быть обобщена через мультиноминальную логистическую регрессию [1], которая позволяет решить задачу многоклассовой классификации. Для задач многоклассовой классификации алгоритм будет выводить полиномиальную модель логистической регрессии, которая содержит K − 1 бинарных моделей логистической регрессии, регрессированных по первому классу. При наличии новых данных будут запущены модели K − 1, и в качестве прогнозируемого будет выбран класс с наибольшей вероятностью.
В Spark MLlib включены две реализации логистической регрессии:
- мини-пакетный градиентный спуск (mini-batch gradient descent),
- алгоритм BFGS с ограниченной памятью (Limited-memory BFGS) [2]
Разработчики Apache Spark рекомендуют использовать реализацию L-BFGS, поскольку она сходится быстрее.
Пример логистической регрессии Spark MLlib
Для примера возьмем данные, которые находятся в репозитории Apache Spark. Для начала преобразуем исходные данные в формате LabeledPoint, где меткой будет первый столбец, а вектором – все остальные.
Пример кода на Python для получения RDD из сходных данных:
from pyspark.mllib.regression import LabeledPoint
def parsePoint(line):
values = [float(x) for x in line.split(' ')]
return LabeledPoint(values[0], values[1:])
data = sc.textFile("data/mllib/sample_svm_data.txt")
parsedData = data.map(parsePoint)
Заметим, что в исходных данные столбцы разделены пробелом, поэтому и используется split(' ').
Для обучения модели логистической регрессии Spark MLlib вызывается метод train. Самым первым аргументом он принимает входные данные в формате LabeledPoint. Также в качестве параметров можно передать:
iterations– количество итераций (по умолчанию: 100),initialWeights– начальные веса (по умолчанию: None),regParam– параметр регуляризации (по умолчанию: 0.0),regType– тип регуляризации. Поддерживаемые значения:"l1"для L1-регуляризации (L-BFGS не поддерживает);"l2"для L2-регуляризации;Noneбез регуляризации (по умолчанию);
intercept– использовать или нет смещение (по умолчанию: False),tolerance– значение, при котором алгоритм сходится и останавливается (по умолчанию: 1e-6),validateData– использовать ли данные еще и на валидацию (по умолчанию: False),numClasses– количество классов (по умолчанию: 2),
Особенно стоит отметить параметр numClasses. Не забудьте поменять его значение, если у вас многоклассовая классификация. Добавим также, что реализация L-BFGS не поддерживает L1-регуляризацию, в то время как SGD ее поддерживает. Когда L1-регуляризация не требуется, настоятельно рекомендуется версия L-BFGS, поскольку она сходится быстрее и точнее по сравнению с SGD путем аппроксимации обратной матрицы Гессе с использованием квазиньютоновского метода.
Обучение логистической регрессии
В примере от Apache Spark всего два класса, поэтому параметр numClasses мы опустим. Код для обучение логистической регрессии Spark MLlib выглядит следующим образом:
model = LogisticRegressionWithLBFGS.train(parsedData)
Получим предсказания обученной модели в виде RDD. Также посчитаем точность модели, посчитав отношение количества правильных вариантов к общему количеству:
trainErr = labelsAndPreds.filter(lambda lp: lp[0] == lp[1]).count() trainErr = trainErr / parsedData.count() # Точность равна 0.753
Чтобы сохранить модель машинного обучения Apache Spark, вызывается метод save; а чтобы воспользоваться сохраненной моделью, используется метод load:
from pyspark.mllib.classification import SVMWithSGD, SVMModel model.save(sc, "SVMWithSGDModel") sameModel = SVMModel.load(sc, "SVMWithSGDModel")
О том, как обучать свои линейные и нелинейные модели на реальных данных, вы узнаете на специализированном курсе по машинному обучению «Машинное обучение в Apache Spark» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

