В предыдущей статье мы говорили об установке GraphFrames на свой компьютер. Сегодня начнём работать с этой библиотекой. Читайте в этой статье: как создать граф GraphFrame, какие условия должны быть выполнены, манипуляция с графами, фильтрация DataFrame, нахождение степени вершины и компонента связности.
Создаем граф GraphFrame
Для того чтобы создать граф GraphFrame, требуется два DataFrame, удовлетворяющие требованиям [1]:
- DataFrame с вершинами (vertex), который должен содержать столбец
id(идентификатор ID вершины); - DataFrame с ребрами (edge), который должен содержать столбцы
src(из какого ID узла идет ребро) иdst(в какой ID узла попадает).
Оба датафрейма могут иметь и другие столбцы, но для конструирования графа перечисленные обязательны. Тип у обязательных столбцов может быть любой, но должен, понятное дело, совпадать.
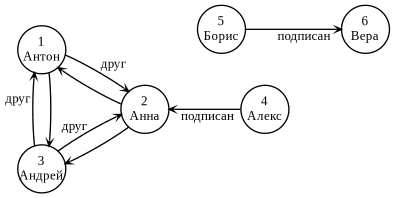
Покажем на примере. На рисунке выше изображен граф, который иллюстрирует некую социальную сеть: друг или подписан на человека. Здесь можно заметить, что граф ориентированный, причем между вершинами может быть две связи (друзья) или одна (подписан).
Итак, чтобы создать граф DataFrame с вершинами ребрами должны быть переданы на вход объекту GraphFrame:
from graphframes import GraphFrame
v = spark.createDataFrame([
(1, 'Anton', 23),
(2, 'Anna', 27),
(3, 'Andry', 24),
(4, 'Alex', 32),
(5, 'Boris', 55),
(6, 'Vera', 64), ],
['id', 'name', 'age'])
e = spark.createDataFrame([
(1, 2, 'friend'),
(2, 1, 'friend'),
(1, 3, 'friend'),
(3, 1, 'friend'),
(2, 3, 'friend'),
(3, 2, 'friend'),
(4, 2, 'follows'),
(5, 6, 'follows'), ],
['src', 'dst', 'type'])
g = GraphFrame(v, e)
Основные манипуляции с графом
Чтобы узнать методы графа GraphFrames, вызовите функцию dir(g). Через граф можно обратиться к датафрейму с вершинами или ребрами с помощью методов vertices и edges, которые возвращают DataFrame. Код на Python для демонстрации:
>>> g.vertices.show() +---+-----+---+ | id| name|age| +---+-----+---+ | 1|Anton| 23| | 2| Anna| 27| | 3|Andry| 24| | 4| Alex| 32| | 5|Boris| 55| | 6| Vera| 64| +---+-----+---+
Поскольку это обычные датафреймы, то можно отфильтроввывать нужные записи. Например, воспользуемся методом join, чтобы выбрать те вершины, которые имеют хотя бы одного подписчика:
>>> has_subs = g.edges.filter("type = 'follows'").select('dst').distinct()
>>> g.vertices.join(follows, (g.vertices.id == has_subs.dst)).show()
+---+----+---+---+
| id|name|age|dst|
+---+----+---+---+
| 6|Vera| 64| 6|
| 2|Anna| 27| 2|
+---+----+---+---+
Метод degrees возвращает DataFrame, который содержит информацию о степени вершин — количестве входящих и исходящих ребер. Например, вершина под номер 1 (Антон) имеет степень, равной 4, так как в неё входят 2 ребра и из неё исходят 2 ребра; а вершины 5 (Борис) и 6 (Вера) имеют степень 1, так как из 5-й исходит 1 ребро, а в 6-ю входит 1 ребро. Убедимся в этом:
>>> g.degrees.show() +---+------+ | id|degree| +---+------+ | 6| 1| | 5| 1| | 1| 4| | 3| 4| | 2| 5| | 4| 1| +---+------+
А вот методы inDegrees и outDegrees выдадут только те вершины, которые имеют как минимум одно входящее и как минимум одно исходящее ребро, соответственно. Например, 5-я и 4-я вершины не имеют входящих ребер, следовательно, в inDegrees они не будут учтены; наоборот, 6-я вершина не имеет исходящих ребер, следовательно, она не будет учтена в outDegrees:
>>> g.inDegrees.show() +---+--------+ | id|inDegree| +---+--------+ | 6| 1| | 1| 2| | 3| 2| | 2| 3| +---+--------+ >>> g.outDegrees.show() +---+---------+ | id|outDegree| +---+---------+ | 5| 1| | 1| 2| | 3| 2| | 2| 2| | 4| 1| +---+---------+
Компоненты связности GraphFrame
Компонентом связности называется подграф, несвязанный с другими подграфами. В нашем случае всего 2 подграфа: 5-6 и 1-2-3-4. Для нахождения компонентов связности используется метод connectedComponents, который возвращает DataFrame с дополнительным столбцом component. Однако перед его вызовом нужно создать директорию чекпоинтов, делается это следующим образом:
sc.setCheckpointDir('graphframes_cps')
Теперь уже можно найти компоненты связности исходного графа GraphFrames:
>>> g.connectedComponents().show() +---+-----+---+---------+ | id| name|age|component| +---+-----+---+---------+ | 1|Anton| 23| 1| | 2| Anna| 27| 1| | 3|Andry| 24| 1| | 4| Alex| 32| 1| | 5|Boris| 55| 5| | 6| Vera| 64| 5| +---+-----+---+---------+
Здесь числа 1 и 5 являются уникальными идентификаторами компонент, они могут быть и другими, главное чтобы они были уникальными. Заметим также, что нахождение компонент связности требует поиска в ширину и глубину, и с точки зрения нотации “O” большого займёт O(n+m) времени, где n — количество вершин, m — количество ребер [2]. Также можно определить компоненты сильной связности — это когда из вершины a можно добраться до b, так и из b в a [3]. В нашем примере есть только одна компонента сильной связности — 1-2-3. Находится компонента сильной связности с помощью метода stronglyConnectedComponents.
В следующей статье рассмотрим, как находить структурные шаблоны в графе (motif finding). Ещё больше подробностей о работе с графами в Apache Spark вы узнаете на нашем специализированном курсе «Графовые алгоритмы в Apache Spark » в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:

